


「孔雀計劃:中文字體排印的思路」系列倡導從中文出發、以中文的思維方式討論中文排版。從本文起將重點分析幾個中文的特殊標點符號。希望讀者可以結合本系列之前關於「擠擠總是有的」「避頭尾」等幾項內容一起來閱讀分析。
2016 年 7 月「知乎 LIVE」新上線,而本站作者、多語言字體技術開發者梁海隨即在其知乎專欄里發布了一篇名為《破折號好難啊!破折號怎麼這麼難!》的文章。他在文章里附上了 2016 年 7 月 8 日在推特上發的截圖,並對 1024 場次「知乎 LIVE」中使用的 907 個破折號進行了統計,結果發現居然有 11 種用法,情況之複雜以致於他說「嗯……我懶得分析了。」既然如此,筆者就接這一棒,為大家分析一下為什麼破折號這麼難。
目錄
破折號到底是什麼?
與其他常用標點符號一樣,破折號也是在十九世紀末二十世紀初現代中文新式標點符號形成過程中從西文引入的一個符號,與其關係最為密切的,當屬西文里的半角連接號 en dash (–) 和全角連接號 em dash (—)。這其中具體的演變歷史甚為複雜,遠超本文所能論述的範圍,但基本上可以籠統地說,由於漢字面積比西文大得多,在上世紀初將西文符號引入中文時,都按「半身」「全身」的倍數關係,將包括空格在內的很多符號放大了一倍。這樣不僅與方塊漢字更搭配,而且,拉長後的破折號還能預防橫排時與漢字數字「一」、直排時與「丨」(豎)混淆。於是一個「佔兩個字寬」的符號就這樣逐漸在現代中文裡穩定下來。經過歲月變遷,隨着中文標點符號的格式與使用方法日趨規範,時到今日,連小學的語文教學裡都會說,破折號應該是「佔兩格的一條橫杠」。目前,在中華人民共和國的推薦國標 GB/T 15834-2011《標點符號用法》里,相關記述如下:
4.10 破折號 4.10.1 定義:標號的一種,標示語段中的某些成分的注釋、補充說明或語音、意義的變化。 4.10.2 形式:破折號的形式是“——” (中略) 5.1.4 破折號標在相應項目之間,佔兩個字位置,上下居中,不能中間斷開分處上行之末和下行之首。
和連接號傻傻分不清楚
但正是因為「一條橫杠」的外觀與另外一個標點符號「連接號」酷似,導致很多人「傻傻分不清楚」這兩個標點符號。我們再來看看同一份國標對「連接號」的相關記述:
4.13 連接號 4.13.1 定義:標號的一種,標示某些相關聯成分之間的連接。 4.13.2 形式:連接號的形式有短橫線“–”、一字線“—”和浪紋線“〜”三種 5.1.6 連接號中的短橫線比漢字“一”略短,佔半個字位置;一字線比漢字“一”略長,佔一個字位置;浪紋線佔一個字位置。連接號上下居中,不出現在一行之首。
其實從用法上說,二者差別可以簡述為「斷」與「連」,即破折號強調「斷」,比如插入說明、轉變話題、引出下文、聲音延長、話語中斷等;而連接號強調「連」,表示連接或者起止。只要牢記這個原則,在用法上應該不難區別。
然而在形態方面,對比國標 5.1.4 與 5.1.6 的描述可知,除了「浪紋線」以外,破折號與連接號的「短橫線」「一字線」的位置都是「上下居中」,因此這幾個符號只能通過長度進行判斷。從實際使用的角度來說,這增大了區別這幾個符號的難度;而從設計的角度來說,這也突顯了繪製這幾個符號時「長度」的重要性。
一個符號還是兩個符號?
其實,冷靜地從零開始再次認真閱讀國標中的定義,我們不難發現,從正確的邏輯上說,破折號是一個符號占「兩個字位置」,而不是將兩個字符合成一個。
雖然「佔兩個字寬的一個字符」聽起來很怪異,但在傳統的鉛字排版里完全不成問題。現代金屬活字在歐洲誕生時,由於主要是鑄造「比例寬度」的西文字母,各個鉛活字的字身本來就有各不相同的字寬。對於破折號,只要直接鑄到一個「佔兩個字寬」的「兩倍」字身上即可(有時也沿用日文稱「倍角」)。反而是到了近現代,打字機的字體都是等寬,而早期計算機更是無法處理「佔兩個字寬的一個字符」,因此只好採用變通辦法,通過重複兩個全角橫杠來代替實現。這並不是設計中文打字時一拍腦袋的決定,而是模仿了英文打字里做法。早期一些西文打字機為了節約鍵位,連數字 1 和字母 I 都能兼用一個鍵位,而用兩個連字符代替西文 dash 的做法已經還算是還原度很高了。很明顯,這是當時在技術限制下的一種變通方法,從理論上和邏輯上說並不能算完全正確,而到現在更不需要照搬。

因此,如果要提破折號的需求,首先它必須是一條橫杠,絕對不能斷成兩條。這原本是一條很基本的要求,但目前在很多實作里往往做不到,比如讀者此時此刻的閱讀環境下看到這篇文章里的破折號也許就是斷開的。而正是因為用兩個符號拼接才導致了各種問題,比如被顯示成斷開的兩條橫杠,甚至在換行時被分成兩截、前一半在前行行末、後一半在後行行首等等原本不應該出現的錯誤。如何解決這個問題,將在下文展開討論。
不單純是斷開問題
破折號的第二個需求是位置問題。上述國標指出,中文的破折號、連接號以及各種括弧、省略號都應該「上下居中」,也就是在正方形字框里垂直方向的正中央。這與西文里的這類標點不同。由於西文標點的設計目的是要與具有升部和降部的小寫字母搭配,因此西文里的這類橫杠類標點的位置往往比中文標點要低一些,比如西文連字符用在中文裡就感覺位置下沉,而西文的兩條全角連接號即使能連起來,位置也不在漢字字框的上下中央。這其實涉及到中西文混排的問題,將在下文展開說明,但單就中文標點的來說,需求其實很簡單,就是必須要上下居中。

第三個需求,也是被很多人忽視的一點,是破折號的長度問題。從一個追求完美的設計師的角度來看,儘管破折號要求佔兩個字寬,但是最好不要頂格。也就是說,這條橫杠最好不要左右撐滿字符框,而是要留有一些喘息的空間。在設計漢字時,除了需要一個虛擬字身的「字框」以外還有一個「字面框」,每個漢字不可能所有筆畫都把字框撐滿,否則「原始字距」變成零之後,在以「密排」為基礎的排版里相鄰漢字全部會粘到一起。漢字如此,標點符號設計也是如此。儘管破折號是一條橫杠,但最好在其兩端留下一些空間。當破折號前後緊跟漢字「一」時,比如遇到「表裡如一——一一分辨」這樣的句子,是否能讓讀者看清楚就顯得非常重要了。「活字」之所以「活」,是因為它能與各種不同的字搭配,必須要考慮到一些特殊情況。
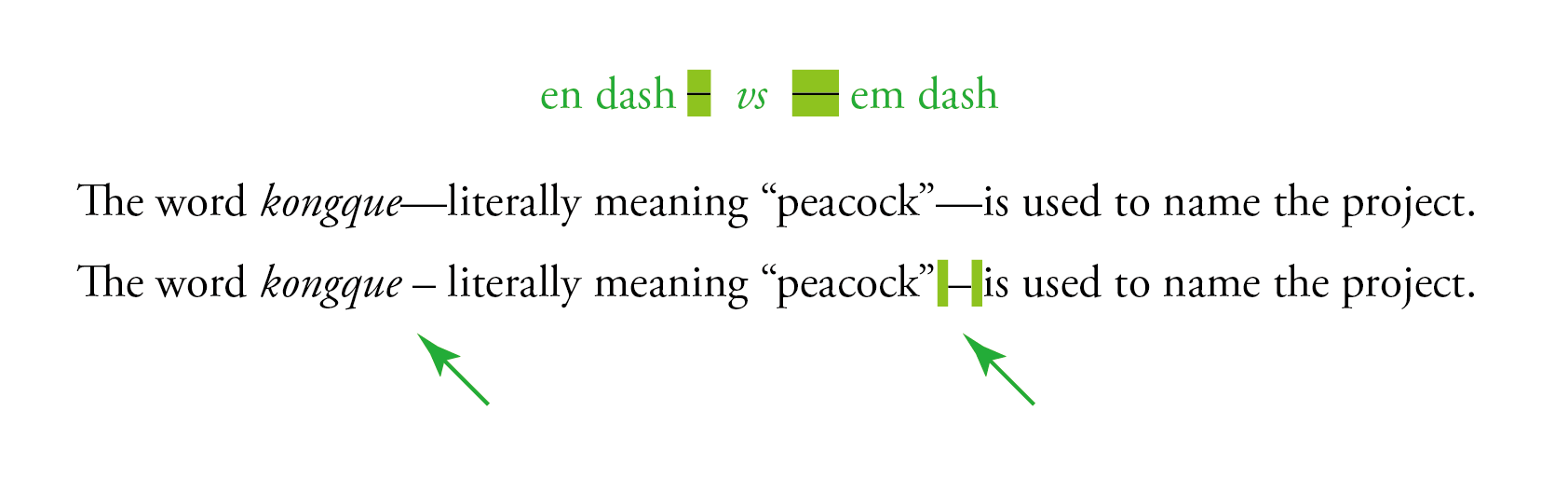
這條需求其實和英式排版里 en dash 的用法有異曲同工之妙。美國「芝加哥風格」與英國「牛津風格」里都寫到1,在長文章排版里,很多英國出版社(但牛津出版社本身除外)偏好在本該使用 em dash 的地方改用前後加空格的 en dash 的方式,這樣可以讓讀者在視覺上感覺橫杠不致於貼着文字太近。
當然,除此之外,破折號在設計上還有其他需要考慮的要素,比如破折號這條橫杠在不同字重、字號下的粗細變化問題。漢字字體中粗細問題涉及到筆畫筆形、文本灰度等諸多要素,根據字體的設計理念有不同處理方法,不能做硬性需求,只能靠設計師在設計上進行定奪,可以做進一步討論。而上述的提到的三點,則應該是作為基本要求需要實現的。但目前的情況是,這些需求在具體實作中都會遇到從輸入到顯示、從字庫到排版各個層面的問題,本文接下來就開始仔細分析。
破折號的碼位
如前所述,金屬活字時代的鑄字廠可以用不同字身,分別鑄造不同大小、長短的鉛字供印刷排印時區分使用;可是到了數碼時代需要鍵盤輸入時就一頭霧水了:上述國標並沒有給出明確的碼位,計算機編碼制定人員與輸入法、字庫廠商對該符號分別做了不同解讀,導致各種實作非常混亂。而作為用戶,很多電子設備使用者也不在意細微的區別,也沒有認真學習輸入法,輸入時隨便挑一個長得像的符號套用。更令人頭疼的是,互聯網通訊便利反而加速了錯誤用法的傳播,看多了錯誤的用法,反而覺得習以為常、見怪不怪了。
在數碼時代我們首先需要的,是在字符編碼層面(如 Unicode)為中文的破折號找到一個正確的碼位。問題是,這個碼位在哪兒?
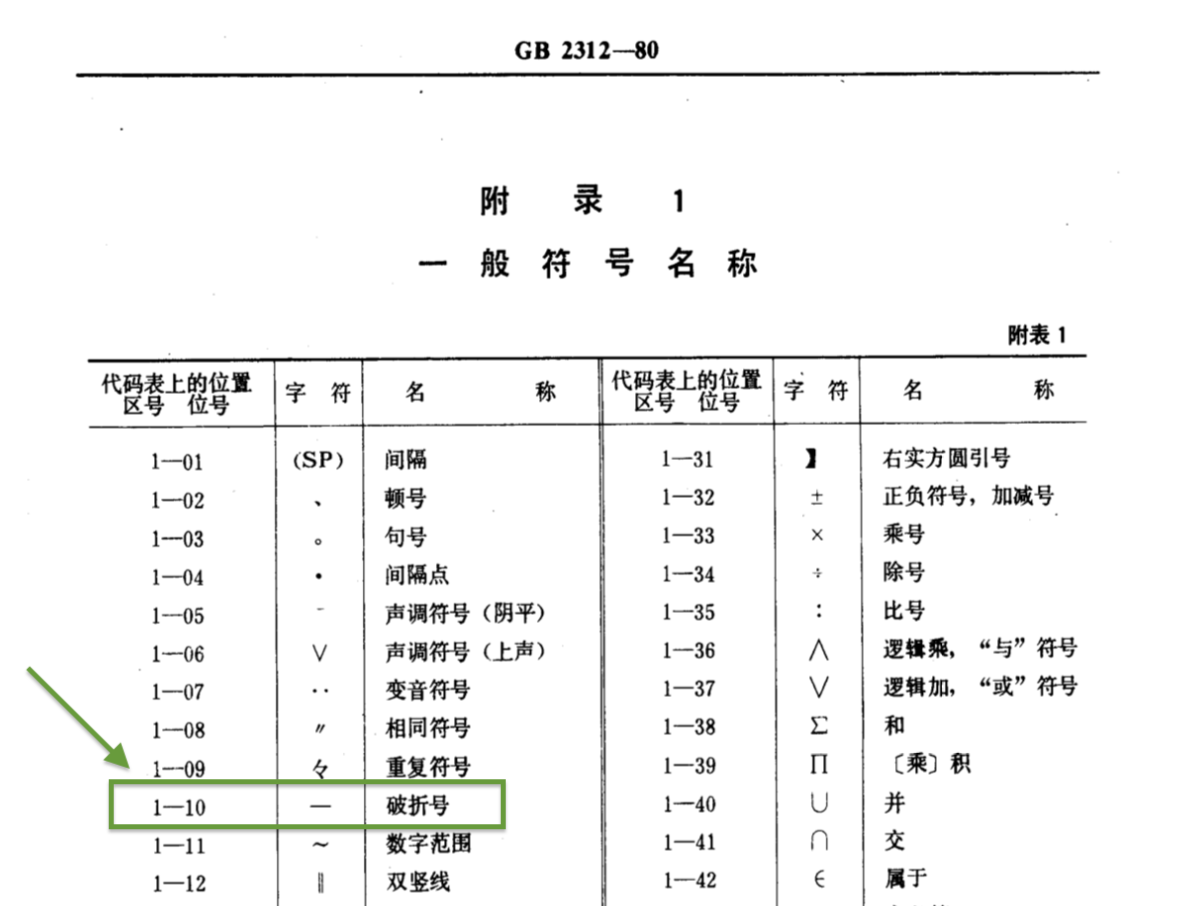
東亞各地區的標準化機構在上世紀七八十年代陸續為各自地區的字符製作了字符集編碼,比如日本工業標準有 1978 年發布的 JIS C 6226(現已改為 JIS X 0208)、中國大陸國標有 1980 年發布的 GB-2312、港台還有 1983 年發布的大五碼(BIG5)等等。查閱中文編碼初創期的資料可以發現,在 1980 年版的 GB-2312 里,1-10 區位上的符號名稱即是「破折號」。而事實上這個 GB 標準幾乎是照搬了日本 JIS C 6226 的結構和順序,這其實為後來 Unicode 映射錯誤埋下的隱患。但最重要的是,這個符號雖然名叫破折號,但明顯是一個只有一個漢字字寬、所謂「全角」的字符。出於早期的計算機功能限制,在編碼當初就已經決定要用這樣一個所謂的全角符號去拼接破折號的做法。
Unicode 這個大雜燴
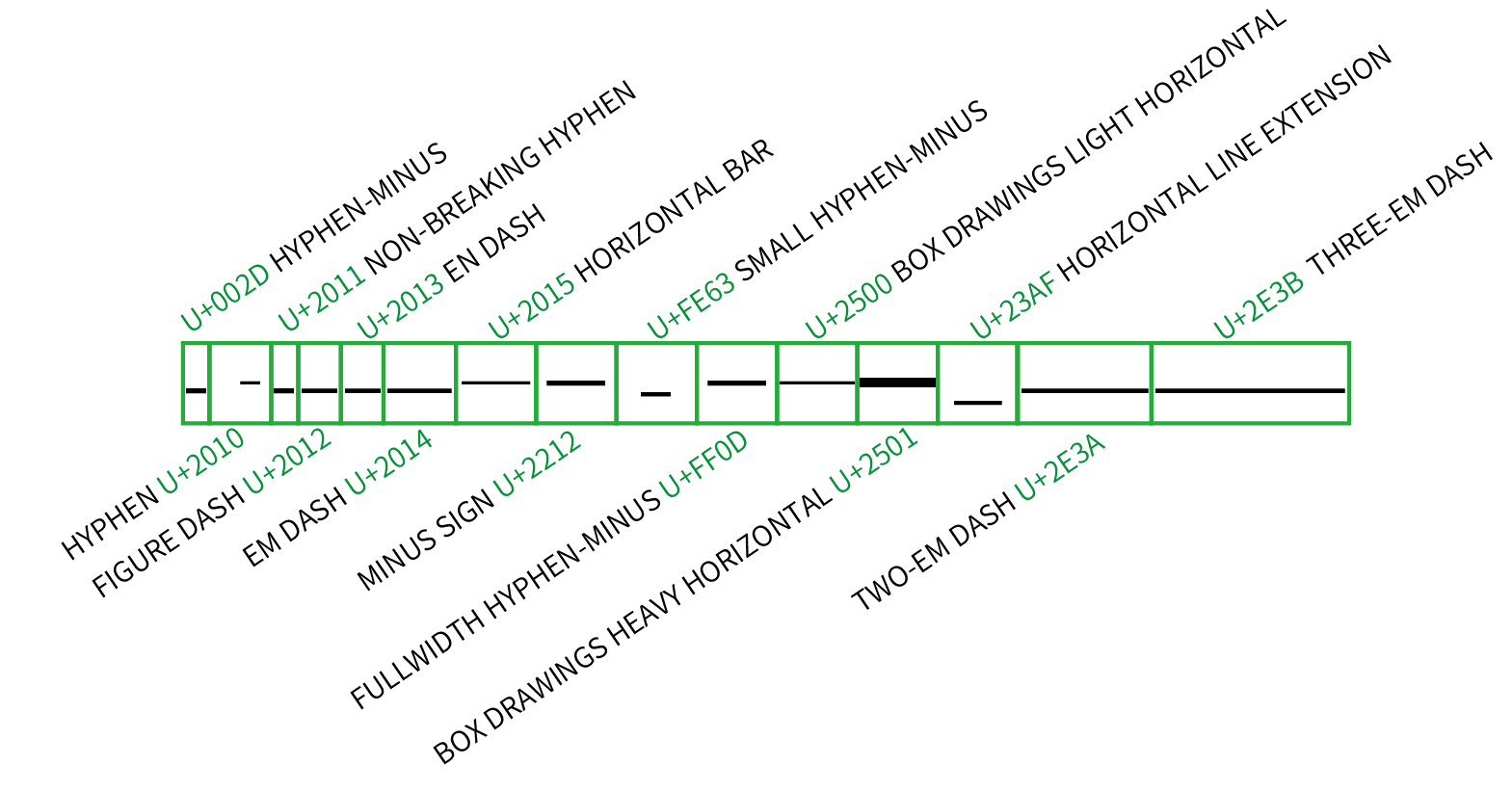
經過萬「碼」奔騰、亂碼橫行的時代之後,字符的編碼技術逐漸向 Unicode 靠攏。由於要收錄全世界各種書寫系統的字符,目前 Unicode 里已經定義了大量與連接號和破折號相關的橫杠字符。比如在西文里,除了常見的連字符「-」、en dash「–」、em dash「—」之外,有數字連接號(Figure dash)「‒」等等。西文字體排印里會用數字連接號分隔數字,比如 130-1234‒5678 這樣的電話號碼里,其寬度與普通數字搭配,但不能表示範圍(因為表示範圍在英文要用 en dash)。這些在精細的字體排印實作里都會嚴格區分,而在一般運用上往往會被不明真相的用戶混做一團。
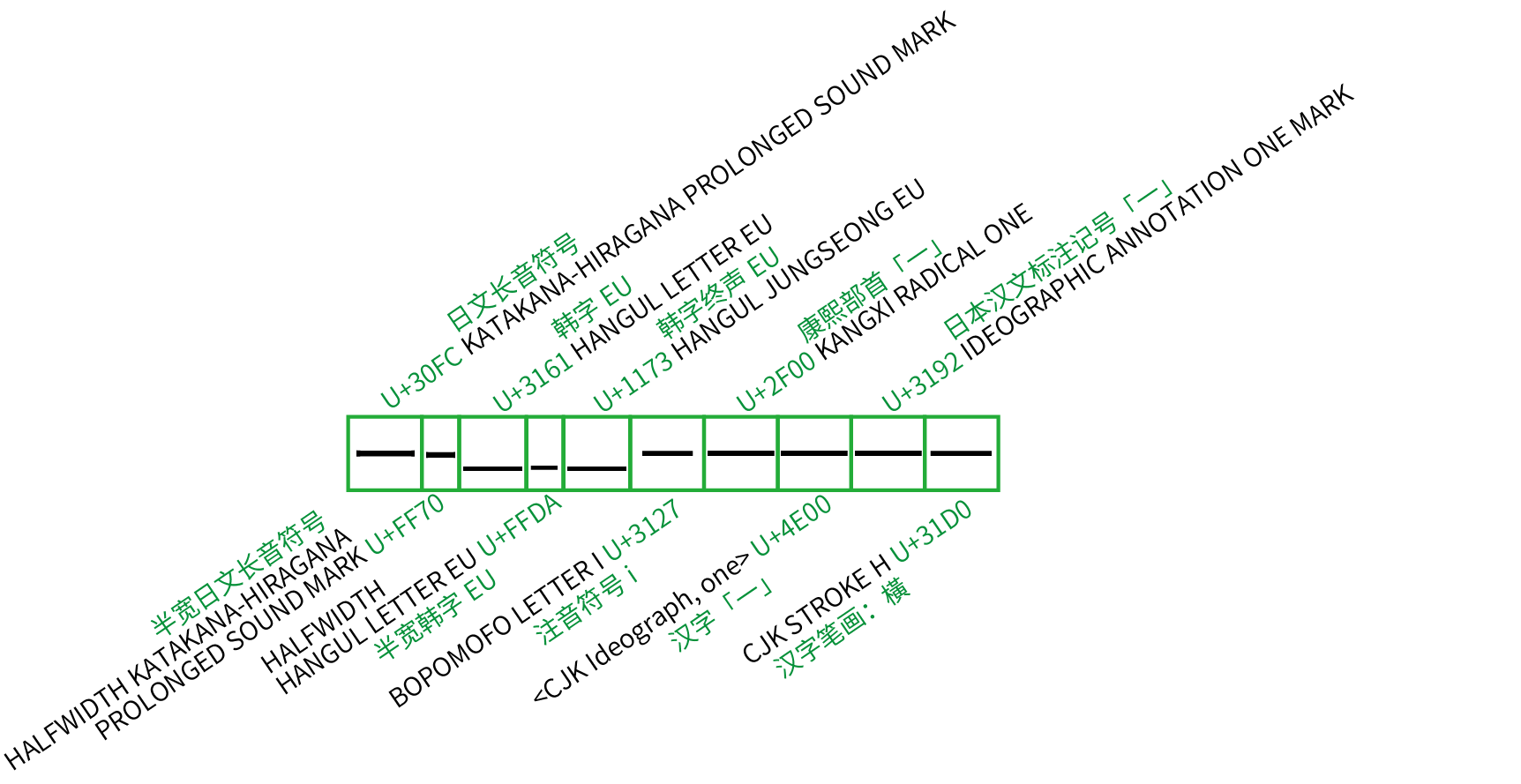
如果再放眼到西文以外的區塊,「長得像一條橫杠」的字符更是多達幾十個:漢字「一」、韓字 eu「ㅡ」、日文長音符「ー」、製表符「─」甚至表情符號的減號「➖」,通過黑體、無襯線體這類字體渲染之後都長得非常雷同,讓用戶莫衷一是。偷懶的用戶可以隨便在符號列表裡挑一個長得像的矇混過關,拿日文長音符充當中文破折號這樣的尷尬排版也屢見不鮮。
2014 還是 2015,這是個大問題
從用法來說,Unicode 里與破折號關係最近的似乎應該是「全角連接號」 U+2014 EM DASH,這也是目前大部分實作的「事實標準」。顯然,這個碼位要表示的原本是一個西文的標點,拿到中文裡用首先會導致中西文標點共用同一個碼位的問題,實際顯示效果往往會根據不同字體而異。正如前文所說,一般的西文字體里由於要與拉丁小寫字母配套設計,橫杠位置會水平偏下,顯然不符合中文破折號的需求。當然,中文字體廠商則會在這同樣的碼位上放上一個水平居中的橫杠,用戶必須選擇中文字體才能正常顯示。這種中西文標點共用碼位的情況並不僅限於破折號,它與蝌蚪引號(“”)等符號一樣,總是會在中西混排時引發很多麻煩,在此就不多展開了。
再來看看這個碼位旁邊的那個叫「橫杠」U+2015 horizontal bar 的字符。在《Unicode 核心標準》第 6.1 章里明確寫到它「在一些字體排印風格里用於引出一段引文」,而碼錶里也明確註明 2015 HORIZONTAL BAR = QUOTATION DASH,這個用法也是中文破折號的用法之一,從用途上說,這個碼位也可以拿來用作破折號。
另外,如果重視上述破折號需求二的位置問題,有人會幹脆用「製表符細橫線」U+2500 BOX DRAWINGS LIGHT HORIZONTAL 這個字符。很明顯,由於這個字符是「製表符」,因此無論什麼字體,其位置肯定是水平居中,而且肯定還是連着的,不管語義是否正確,至少從形式上一了百了地解決了一些問題。

另一方面,從各地標準轉換到 Unicode 時還有過一些陣痛。東亞各地區的編碼用在各自的系統里並沒有問題,但是後來 Unicode 出現之後,需要將本地字符與 Unicode 規整、映射,於是各種各樣的問題層出不窮,其中最典型的例子就是「CJK 統一漢字」的認同 (unification),而破折號也不幸陷入其中。
作為東亞字符編碼的先驅,JIS 本身曾經有過一段烏龍。JIS X 0208 及 JIS X 0213 字符集在 1 面 1 區 29 點裡安排了一個「連接號(全角)」,並定義其在 Unicode 的對應名稱為 EM DASH。按照這個名稱,理論上就應該是 Unicode 里的 U+2014。然而後來的 JIS X 0213:2000 卻錯誤地將這個符號映射到了 U+2015,直到 2001 年 5 月才發布《勘誤表》急忙訂正回來,直到後來 2004 年 JIS X 0213 修訂的時候才終於回到所謂正確的 U+2014,風波告一段落。
無獨有偶,Unicode 聯盟早年在其 FTP 網站上提供的「非規範」信息里也曾把 Shift_JIS 中 0x815C「連接號(全角)」映射到了 Unicode 的 U+2015 碼位上。雖然目前這個文件已經被官方聲明過期,但使用這個實作的程序時到今日依然存在。微軟公司在 Windows XP 使用的代碼頁 CP932 里也保留了同樣的 Unicode 映射。而蘋果公司針對 Shift_JIS 的 MacJapanese 編碼以及微軟 Windows Vista 之後的 CP932 則已經改回到 U+2014 上。
中國的情況也是如此。在 1993 年 12 月 6 日由 Unicode 技術委員會(UTC)提供、 Glenn Adams 和 John Jenkins 製作的《GB 2312 映射表》中 GB2312.TXT 文件里,就將 GB2312-1980 的 1 區 10 位的字符(字節序 0xA1AA)指向了 Unicode U+2015 HORIZONTAL BAR,雖然該文件已於 2011 年由官方棄用,但影響依舊很大。當然,Unicode 在其後的發布的 GBK 與 GB1830 子集的映射都已經改為 U+2014 EM DASH 碼位。
而廠商方面,微軟公司使用的簡體中文代碼頁 CP936 的最初版本也是映射到了 U+2015,後來在 Windows 95 里將 GB 2312-80 擴展成 GBK 時,將其映射改到了 U+2014。但是,作為歷史遺留痕迹,翻閱微軟的資料即可發現,微軟代碼頁 20936(即簡體中文 GB2312-80)和 10008(即簡體中文(Mac))里的映射依舊是 U+2015。微軟的文檔里清楚地記載了變更:
/* GBK and GB2312 map differently in few code points that are listed below: * gb2312 gbk * A1A4 U+30FB KATAKANA MIDDLE DOT U+00B7 MIDDLE DOT * A1AA U+2015 HORIZONTAL BAR U+2014 EM DASH * A844 undefined U+2015 HORIZONTAL BAR */ 而在蘋果公司的《簡體中文代碼映射表》里,也記載了這些變化:(筆者譯自 CHINESIMP.TXT 2002 年版)
2. 基本 EUC-CN 字符映射 出於以下原因,對一些非漢字的映射從 UTC 映射做了修改, – 為了更好地與中國標準化組織 GBK 映射保持一致(GBK 應該包含所有 GB 2312 字符) (略) 從 n00 版到 n05 版的變更: A. 為配合 GBK 映射(下略)
- 將
0xA1A4映射從U+30FB KATAKANA MIDDLE DOT變為U+00B7 MIDDLE DOT- 將
0xA1AA映射從U+2015 HORIZONTAL BAR變為U+2014 EM DASH
雖然映射關係已改,但是 php-5.6、ActivePerl-5.20、Java 1.7、Python 3.4 依舊使用老版本將破折號映射到 Unicode 的 U+2015 碼位上,這些老版本的影響還遠遠沒有消失,包括微軟 Word 在內的應用軟件,都多多少少會不經意地暴露出一些問題,具體放到下述章節討論。
說好的佔兩格呢
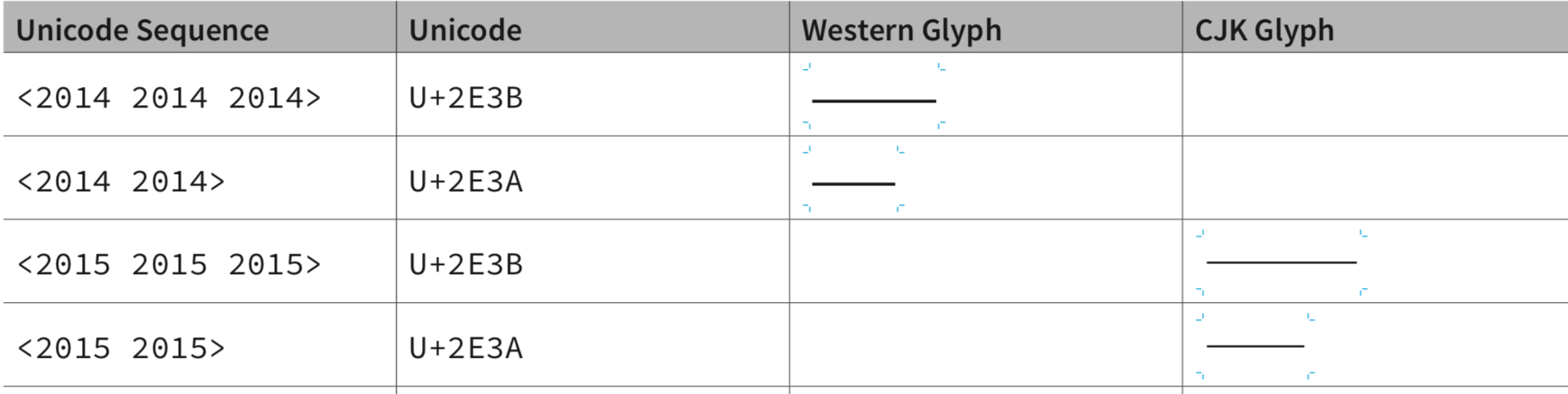
其實,西文的字體排印也存在多個寬度的橫杠符號,隨着後來計算機性能的提高和文字編碼工作的深入,這些符號也相繼被收入到 Unicode 里,比如我們可以看到在 U+2E00 – U+2E7F 的「增補標點符號」 (Supplemental Punctuation) 區塊里就有 U+2E3A TWO EM DASH(兩倍接連號,即「⸺」) 和 U+2E3B THREE EM DASH(三倍接連號,即「⸻」)。
既然中文破折號是一個佔兩個字寬的符號,那麼選用 U+2E3A TWO EM DASH 似乎應該是合情合理的一個選擇。然而,Unicode 里最符合邏輯的碼位並不一定是最常用的。但這個碼位來的太晚,早年打字的習慣已經無法修改,從中國大陸絕大多數的軟件實作以及用戶習慣並沒有用 U+2E3A TWO EM DASH 這一個字符,而是依舊採用兩個映射到 U+2014 EM DASH 拼接成一個破折號。顯而易見,這不僅無法滿足上述的破折號第一需求,而且還為斷開等問題留下了後患。在日常生活中,這樣的實作唯一一個好處似乎是,歪打正着地可以讓用戶可以方便輸入中文連接號的「一字線」。包括筆者在內的用戶,有時候在中文狀態下無法方便地輸入「一字線」,所以乾脆先打一個破折號,再回頭刪除一格。
在筆者參與編輯的W3C《中文排版需求》里,為了尊重既成事實,編輯們決定採用折中處理,目前版本的行文如下:
破折號是佔兩個漢字空間的U+2E3A TWO-EM DASH[⸺]或U+2014 EM DASH[—]。
破折號怎麼輸入
無論內部碼位怎麼變化,對於用戶來說,最關心的還是如何方便地輸入這個破折號。我們再回到本文開頭提到的梁海在知乎專欄《破折號好難啊!破折號怎麼難!》一文。在他的統計里,用戶實際輸入破折號的結果按照順序排列如下:
- 「——」<
U+2014 EM DASH* 2> - 「--」<
U+FF0D FULLWIDTH HYPHEN-MINUS* 2> - 「–」<
U+002D HYPHEN-MINUS* 2> - 「-」<
U+002D HYPHEN-MINUS> - 「—」<
U+2014 EM DASH> - 「-」<
U+FF0D FULLWIDTH HYPHEN-MINUS> - 「— —」<
U+2014 EM DASH,U+0020 SPACE,U+2014 EM DASH> - 「- -」<
U+002D HYPHEN-MINUS,U+0020 SPACE,U+002D HYPHEN-MINUS> - 「—」<
U+002D HYPHEN-MINUS* 3> - 「ーー」<
U+30FC KATAKANA-HIRAGANA PROLONGED SOUND MARK* 2> - 「————」<
U+2014 EM DASH* 4>
看着普通用戶們輸入的這些問題多多的破折號,總體來說可以分成以下幾類:
一、與連接號混淆,因為破折號本身與中西文連接號本來就很難分清; 二、與其他西文符號混淆,比如用西文 hyphen 類的字符; 三、與其他文種的符號混淆,比如日文里所謂「全角」的長音符號; 四、混用其他符號,比如 7. 愣是在兩個字符裡面加入了一個空格; 五、把一個符號單用、雙連用甚至四連用等等
下面我們就來分析一下用戶們在輸入破折號時的各種煩惱。
輸入法的陷阱
依照目前的事實標準,大部分電腦的中文輸入法採用的都是在中文狀態下同時按住 Shift 鍵與減號鍵,這樣會一口氣跳出兩個「全角連接號」 U+2014 EM DASH拼成一個破折號。仔細想來,這種「按一個鍵跳兩格」的操作還真是有些奇妙。在中文標點符號里,只且僅有破折號和省略號這兩個「佔兩個字寬」的標點能享受這種特權。因此,到底是一個字還是兩個字的問題着實讓人糾結。

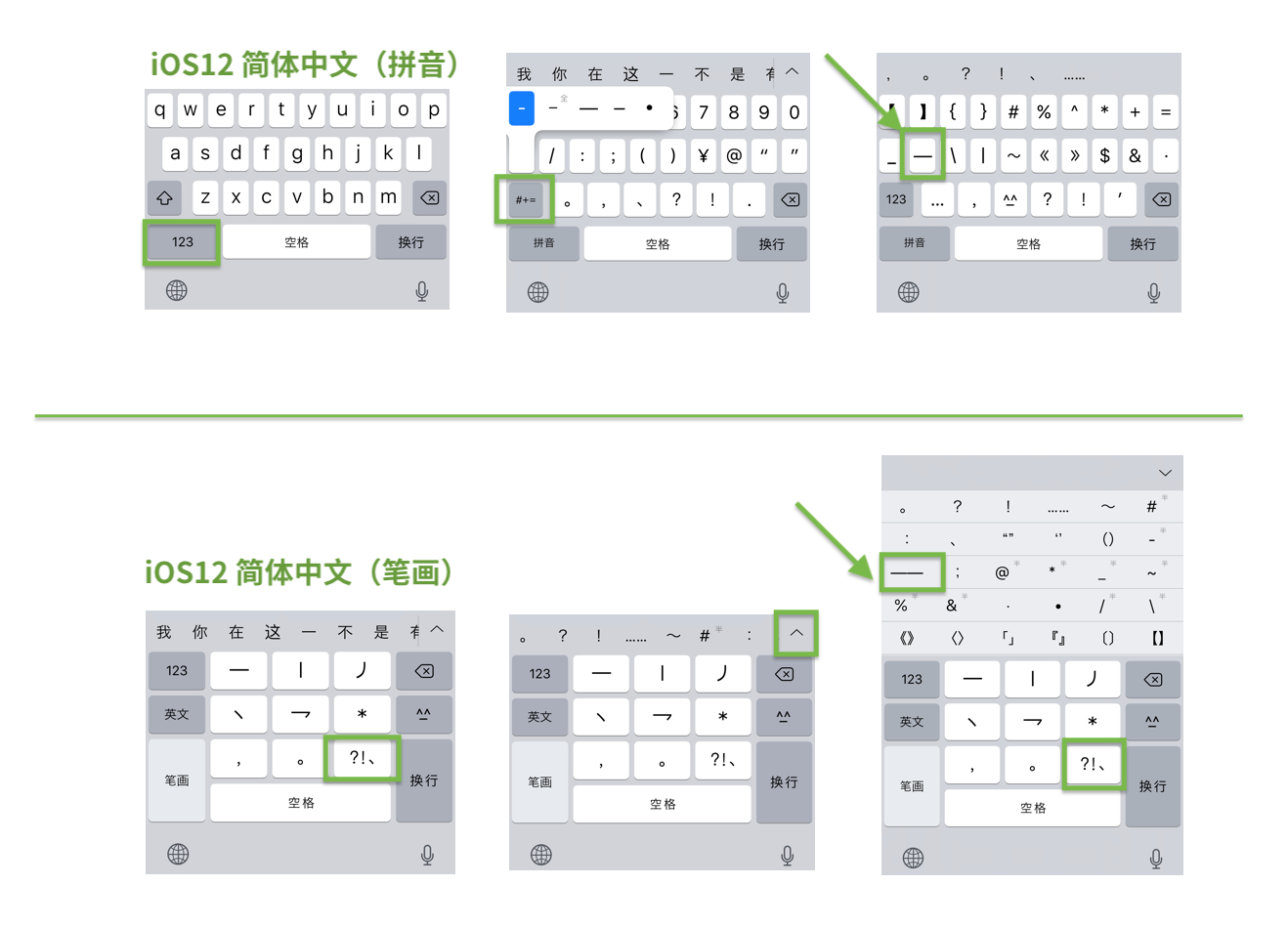
電腦鍵盤的鍵位相對穩定,但手機、平板等移動設備並非如此。由於各種觸屏設備的軟鍵盤以節約空間為最優先要素,對各種符號的鍵位進行了改動,而且往往不同廠商的各個機型、系統的各種方法並不統一,人為地加大了標點符號輸入的困難。比如在 iOS 簡體中文輸入法里,「拼音」和「筆畫」的界面就很不一樣。拼音輸入法里,用戶需要先按一次空格左邊的「123」鍵進入「數字狀態」,再按一次「#+=」鍵才能找到輸入所謂「全角連接號」U+2014 EM DASH 的鍵位,然後用戶需要按兩次來組成一個破折號。由於在第一步進入「數字狀態」時並沒有全角連接號,反而有英文的連字符,這樣的用戶界面導致很多用戶就停在這一步,隨便打幾個連字符代替了事。如果此時利用長按鍵盤的小技巧,按「連字符」鍵調出的更多選項里,各種符號的長短過於近似,一般用戶很難選對。相對地,iOS 簡體中文的「筆畫」輸入法的用戶體驗就非常直接和準確,用戶點按「?!、」鍵即可調出中文標點選項,雖然裡面沒有破折號,用戶也會很自然點擊向上箭頭拉開選項菜單,而其中備選的破折號、省略號都已經是佔兩格的形式,括弧也是成對的,用戶只需按一次即可完成輸入,這個體驗明顯比「拼音」更為友好,直接而沒有誤導。
半路殺出的程咬金:拼寫自動更正功能
將破折號與連接號混淆已經是常見錯誤,似乎還「情有可原」,那麼為什麼用戶會三連用甚至四連用呢?從用戶心理考慮,看到一個西文連接號(-)放在中文裡肯定會覺得的長度不夠,下意識地會要連用。一些用戶一直抱着「西文符號是半角」的固有概念,覺得打兩個「半角」可以湊成一個所謂「全角」,再用兩個全角拼成佔兩格的破折號,於是就連按四下。
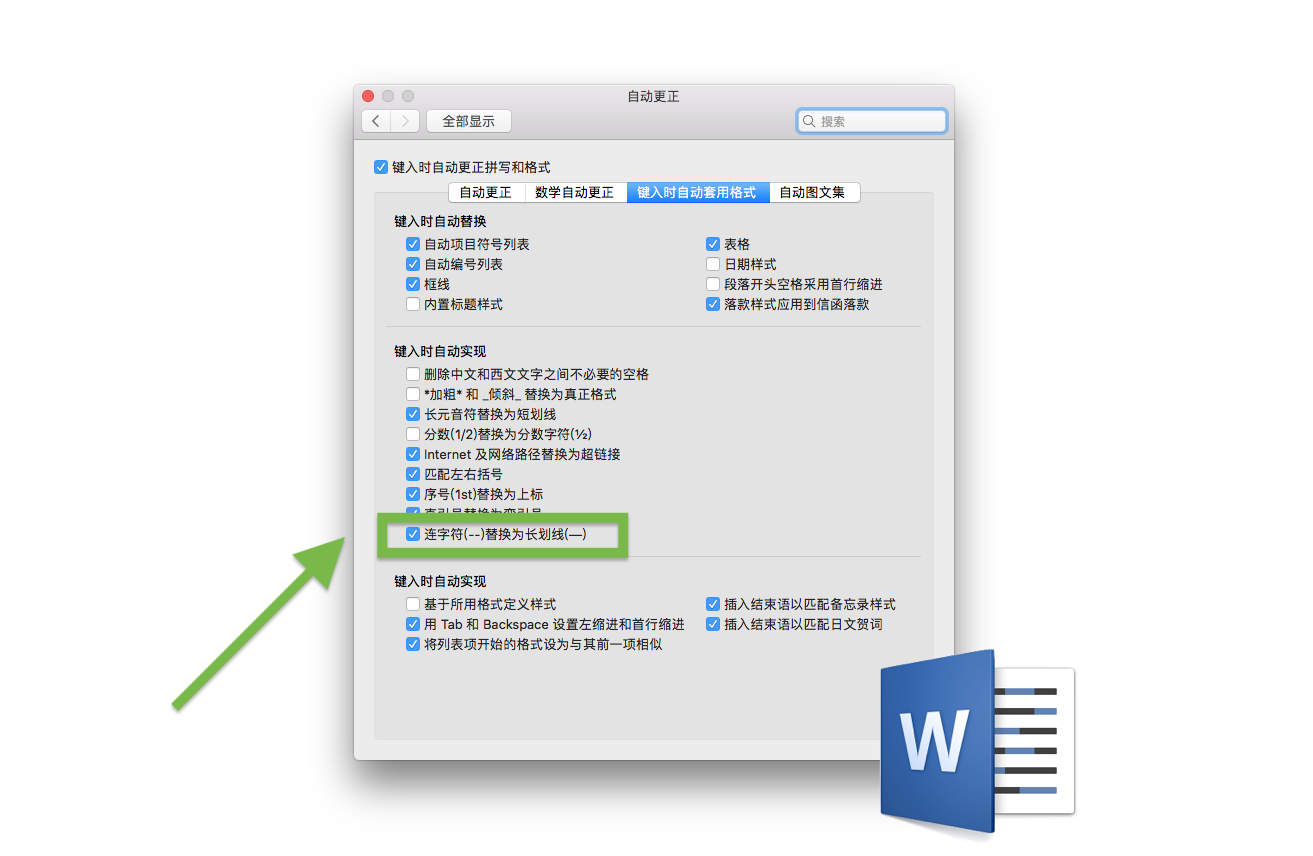
這在一些字處理軟件里往往可以歪打正着地成功輸入破折號,因為有些軟件系統有「拼寫自動更正」的功能。無論是蘋果公司的 macOS 或 iOS,還是微軟 Word,都會默認啟用「自動更正」,而這個功能往往都會將連續兩個西文連字符(hyphen)替換成「全角連接號」的 em dash,即一個 U+2014 (中文版 Word 里稱之為「長劃線」)。
然而,這個體驗並不是連續的。一旦脫離了帶有自動更正的軟件環境,在一些純文本編輯器下,這類連打就不起作用了。正如本文第一章第二節所述,由於西文打字機用戶會打字機替代鍵位的舊習慣輸入西文 dash,因此軟件在「自動更正」里對此設計了這樣一個方便功能,但顯然這並非為中文排版所設。
我們也可以呼籲各種排版引擎考慮增加對中文的需求,但是這個需求是什麼、如何實現才合理,需要認真定奪。比如,如果單純設置將兩個 U+2014 自動替換成一個 U+2E3A TWO EM DASH,這依舊需要字庫的支持。否則,好不容易換到了 U+2E3A TWO EM DASH 而字庫廠商卻又沒有繪製這個碼位的字形,會導致字符無法正常顯示,用戶就會看到「豆腐」或者乾脆什麼都沒有。退一步來說,如果這樣的替換處理不是在文本處理,而是在字體層面利用 OpenType 的 GSUB 特性就解決掉,那麼排版引擎方面就要把工作重心轉移到「全面支持 OpenType 特性」上了。從這一點我們也可以看出,字體排印處理是環環相扣、相輔相成的,一個環節出問題都會掉鏈子,而在哪個層級處理問題,需要對整個環節有正確理解的基礎上再做判斷。
破折號怎麼顯示
無論用戶如何輸入,字符最後要正常顯示輸出,還是要靠字體廠商和排版引擎。早在 2011 年知乎上就有這樣一個問題:「目前網上使用的中文破折號普遍存在「中間斷開」的問題,應該如何解決?」現在,八九年已經過去,讓我們看看現狀是否有改善。
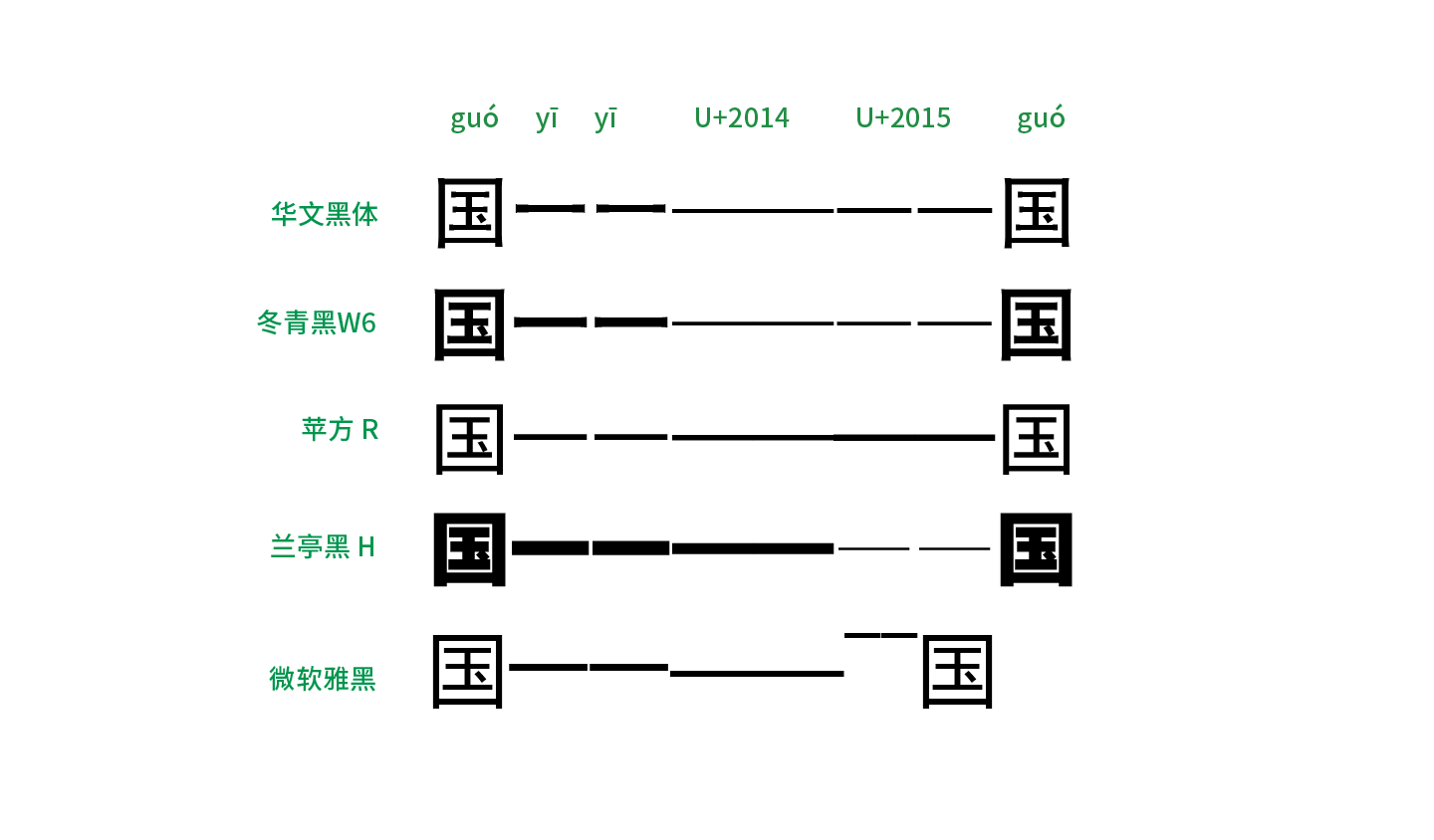
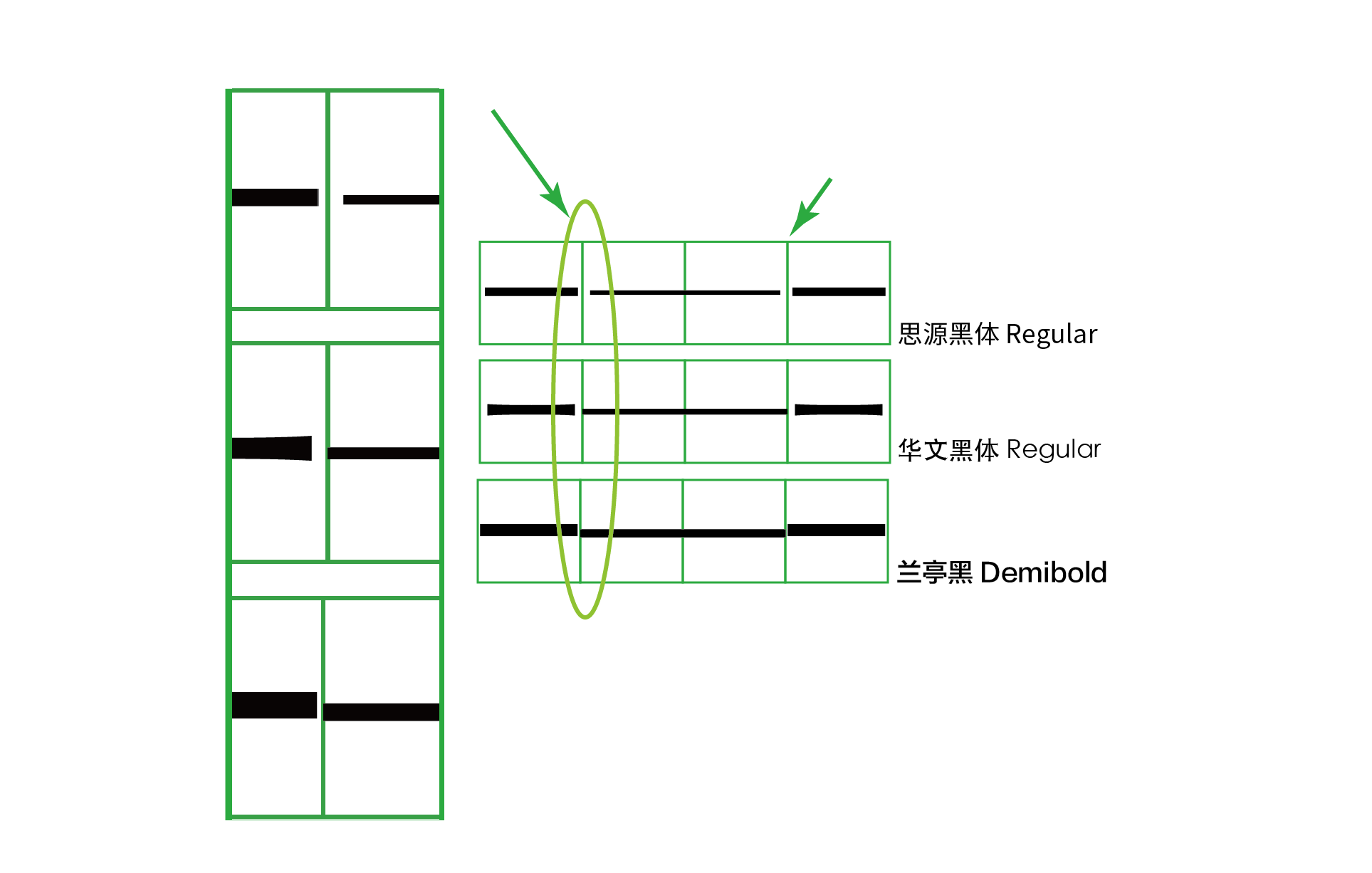
先來看看常用於屏幕顯示的黑體。從上圖羅列出了一些常見的黑體可以看到,針對目前最常用的 U+2014 EM DASH 這個碼位,大部分廠商都將字形製作成位於水平中央、左右撐滿的橫杠,保證了連用不斷開,滿足破折號的前兩個要求。而對於 U+2015 horizontal bar 這個碼位的字形,大部分字體里的字形左右留空,因此兩個連用時會斷開。只有「蘋方」將這兩個字符的字形都做成了左右撐滿,粘在了一起,但似乎用了不同的粗度加以區分。「華文黑體」這樣的老派泛用黑體字庫里,漢字「一」、U+2014、U+2015 三者的粗細都不一樣,加大了區別度。當然,在現代字庫「多字重」的家族展開里,針對「不同字重下的標點粗度是否應該隨字重的變化而變化」這個課題,各個廠家有着不同的解答。比如方正「蘭亭黑 H」的 U+2014 EM DASH 明顯按照 H 字重加粗了,但 U+2015 卻依舊非常細。另外,舊版微軟雅黑里的符號依然「不走尋常路」,U+2014 的字形不僅位置下沉,兩個連用時長度居然還超過兩個字寬,而又把 U+2015 horizontal bar 做成上浮橫線,實在令人哭笑不得。
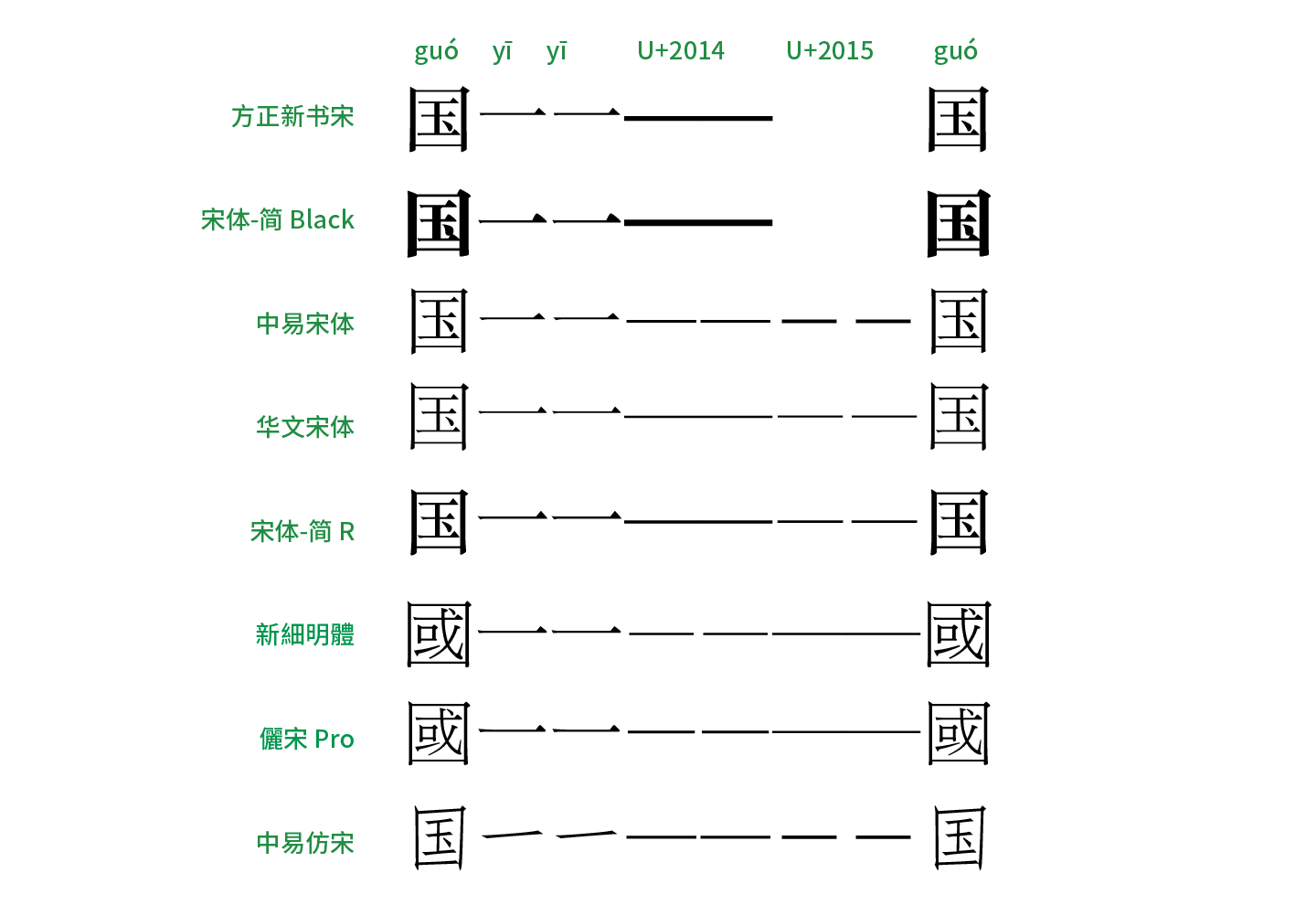
而看看相對多用於正文的宋體、仿宋,在一些舊版字體里,破折號被斷開的慘劇依舊在上演。在圖中還能看出另外一個規律,即中國大陸簡體字庫里基本上都會將常用的 U+2014 做成水平中央、左右撐滿以保證不會斷開,但對於 U+2015 要麼是沒做、導致缺字,要麼是左右留空而斷開。而在繁體字庫則相反,U+2014 的字形連用時會斷開,但是 U+2015 卻可以連起來,這明顯是上述歷史原因以及地區差異造成使用習慣不同而形成的實作。當然,像中易宋體、中易仿宋這樣無論如何都接不上的破折號實在令人心痛,對於這類老字庫,用戶還是避開使用為佳。
然而,針對「兩個字符連成一個破折號」的事實標準,一些新字體進行了新的嘗試。2015 年 Adobe 公司發布的泛中日韓字體「思源」系列就採用了一個相對激進的做法:第一步先使用 OpenType 中的「字形組合」ccmp 特性(即 Glyph Composition),若遇到兩個連續的 U+2014 字符,會將字形直接替換成到與 U+2E3A 一樣的長橫杠;之後的第二步,採用 GSUB 中的 locl 特性切換中日韓區域指定的字形,保證其與漢字字框居中對齊。對於三連 em dash 也採用同樣處理。
第一步的做法其實非常值得向各家字體廠商推薦,因為它保證了破折號不會斷開,這也是現代 OpenType 特性能服務於中文排版的少數實用功能之一。而第二步之所以說「激進」,是因為必須依靠 locl 特性進行西文與中日韓格式切換,而這不僅需要第三方應用軟件的支持,還需要用戶對文本本身進行正確的語言標註。也就是說,需要通過語言標記告訴軟件這是中文,才能調出中式的居中字形,否則,排版軟件依舊會將其認為是西文而顯示西文「下沉」的字形。然而事實上,能支持語言標記的環境還非常少。當思源黑體當年剛發布時,在 Adobe 自家軟件里也只有 InDesign 可用,連 Illustrator 都不支持。從用戶角度說,這也加大了學習成本。從後來字體發布的反饋來看,用戶非常不習慣這種做法,也不太熟悉如何調用 locl 信息,只是一直抱怨無法方便地調出正確的字形。




破折號怎麼排版:避頭避尾避中間
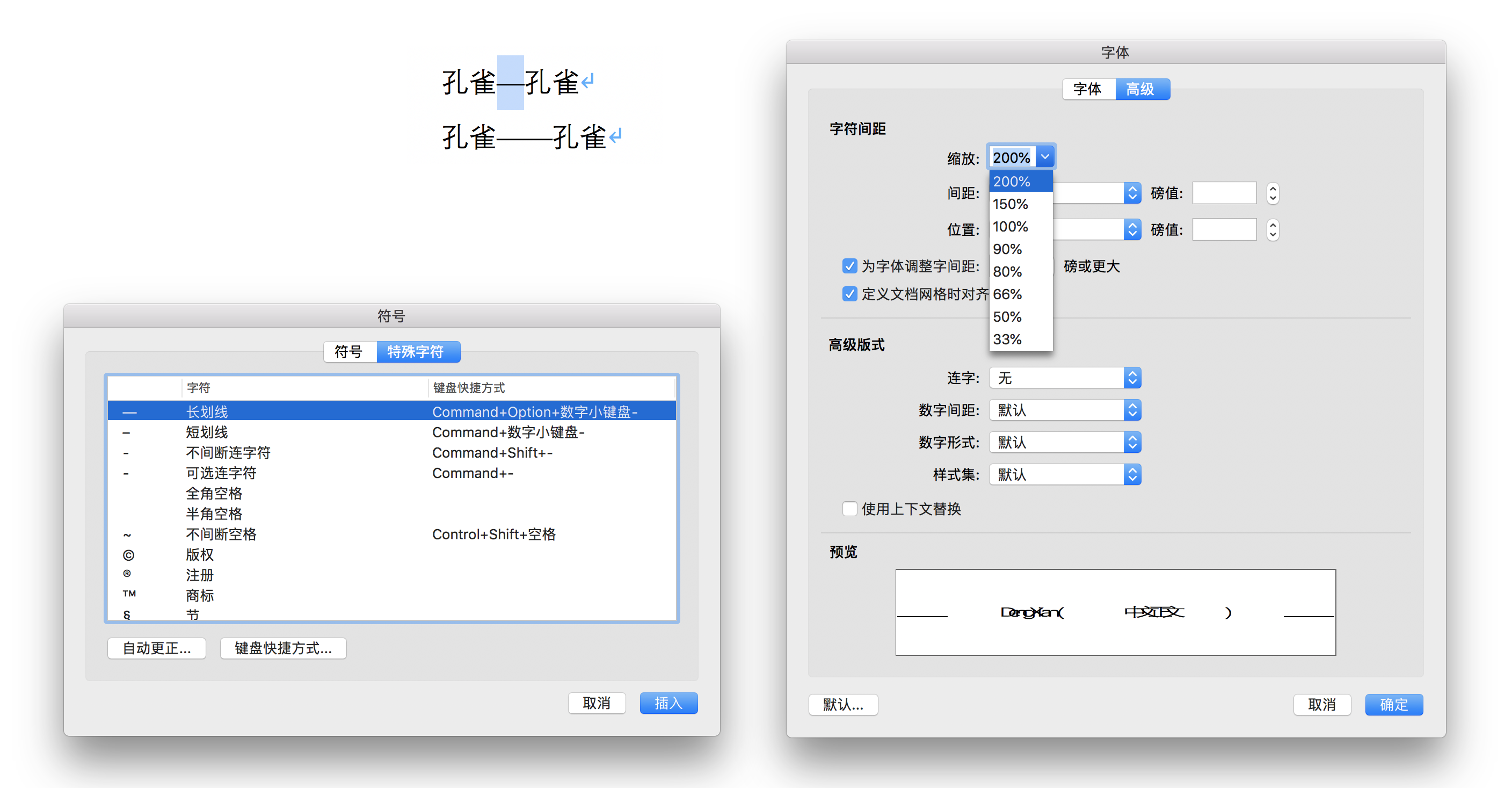
要談破折號怎麼排版,首先應該提一下一些印刷行業出身的老派編輯的做法。他們更傾向於把破折號當做其應有的「一個字符」處理,因此會靠軟件里「字符變形」功能將一個 em dash 字符拉大到兩倍寬。比如,在 2011 年由印刷工業出版社《排版與校對規範(第二版)》里「附錄一:Word 設置的參數」里有這樣記述:
符號字模未設有該符號,需要「字符縮放」完成。「插入→特殊符號→標點符號」選「—」插入後選中,「格式→字體→字符間距→縮放」選 200%
無獨有偶,在特別考慮破折號的第三個長度需求時,一些日本排版專家也一直堅持在 Adobe InDesign 里不要用 U+2500 BOX DRAWINGS LIGHT HORIZONTAL 這樣的製表符,因為這個符號會左右撐滿。他推薦採用 U+2015 horizontal bar 字符,因為日文字庫廠商往往不會將其做成左右撐滿的造型,拿過來之後在軟件里將其拉大到兩倍寬即可。
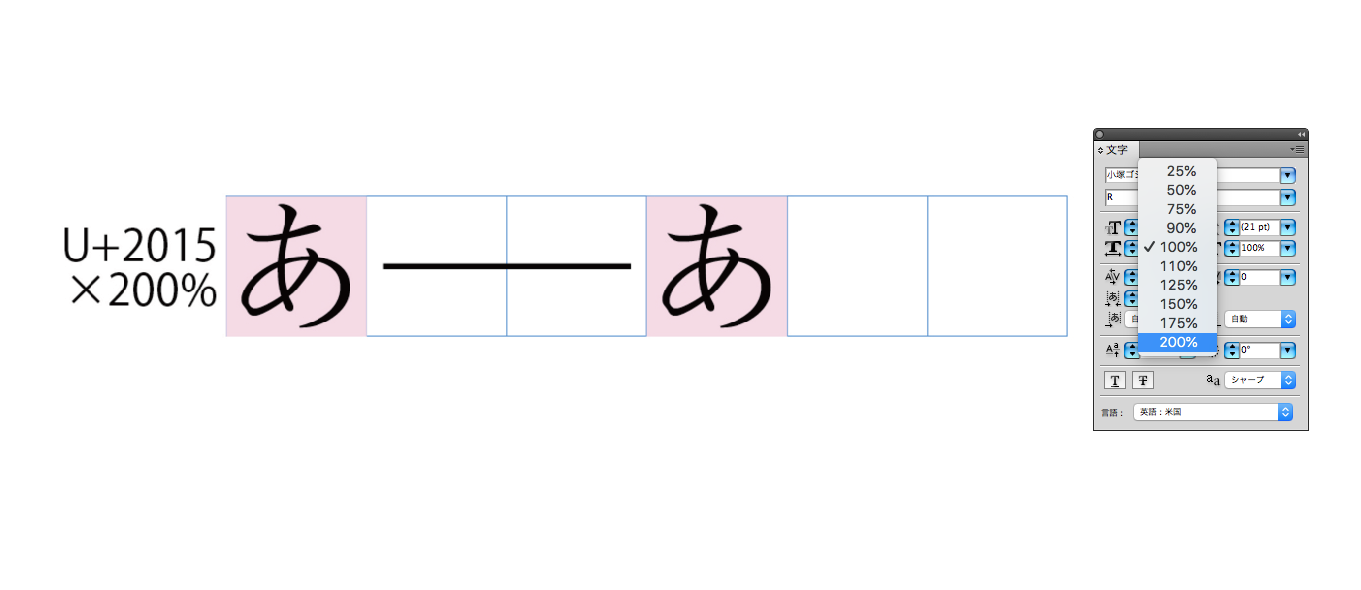
使用一個字符的好處,就是在從根本上杜絕了中間斷開的可能,這看似是一種曲線救國的方式,但從需求本質上說也未嘗不可。當然,大部分非出版行業的朋友並不會這麼做,而且接受的稿件本身絕大多數都是連用兩個全角連接號去拼成一個破折號,這就容易產生從中間斷開的問題。
破折號的排版還有是否需要避頭尾的問題。這一點在中國國標 GB/T 15834-2011《標點符號用法》並里沒有相關記述,而筆者已經在《擠進推出避頭尾》一文里談過,有興趣的讀者可以移步閱讀。總體來說,有一些「嚴式」風格會禁止破折號出現在放在行首,但是由於這個符號佔用了兩個字寬,過於嚴格的規定往往會導致一行內產生大幅度的調整量,反而不利於長文排版的均勻字距的要求。而放寬規則,採用「寬式」風格不對破折號進行避頭尾控制,其實效果並不壞。

在 Adobe InDesign 中文版默認的「簡體中文避頭尾」設置里,U+2014 EM DASH 已被放入「禁止在行首的字符」,也就是說,如果採用默認設置即會變成「嚴式」風格,對破折號進行避頭處理。了解這個默認設置很重要,而需要「寬式」風格的用戶可以根據需要自定義修改。
對於非設計專業的一般用戶來說,需要特別注意的是微軟 Word 軟件的默認設置。在 Word 默認設置里「後置標點」(即避頭符號)里有一個看似破折號的符號「―」,但它並不是目前大多數中文輸入法採用的「—」 U+2014 EM DASH,而是 U+2015 HORIZONTAL BAR。按照這個設置,用戶輸入 U+2014 EM DASH 破折號時, Word 並不會對其進行避頭尾處理。如果想針對破折號進行避頭尾操作,筆者建議用戶通過「自定義」手動添加 U+2014 EM DASH 這個符號。這個問題的根源就是本文在第二章第二節里提到的字符映射發生過修改而產生的歷史問題。無論問題來源是什麼,在實務操作層面,如果要確保對破折號進行避頭尾處理控制,還是將兩個字符都加入避頭尾定義表裡最為穩妥。
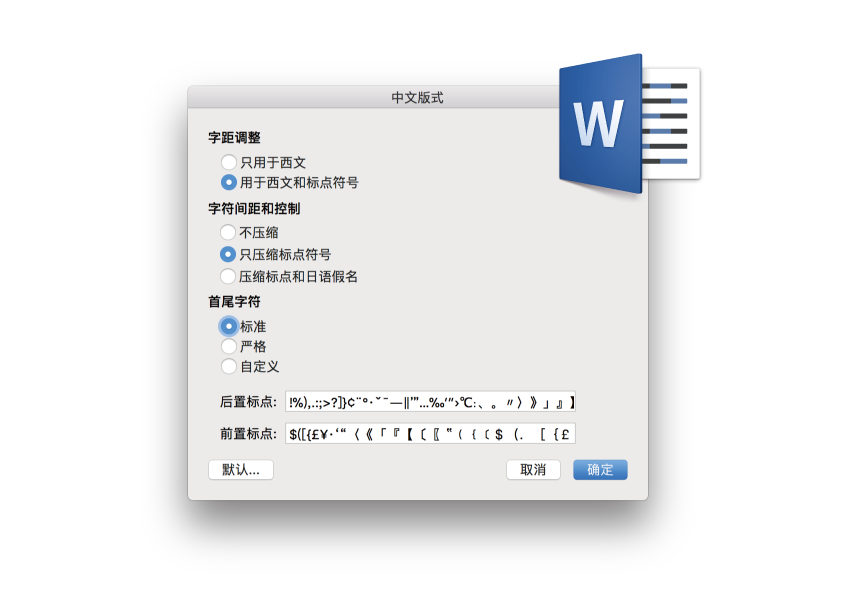
但是,從避頭尾控制的「不可分字段」的角度考慮,破折號除了需要避頭避尾,還有一個特殊的「避中間」問題,即「禁止斷開」,破折號不能從中間段成兩截分別位於前一行行尾和後一行行首。對於這個控制,Adobe InDesign 的操作界面卻存在「禁止分開」「禁止斷字」「不換行」的好幾個選項,讓用戶非常困惑。
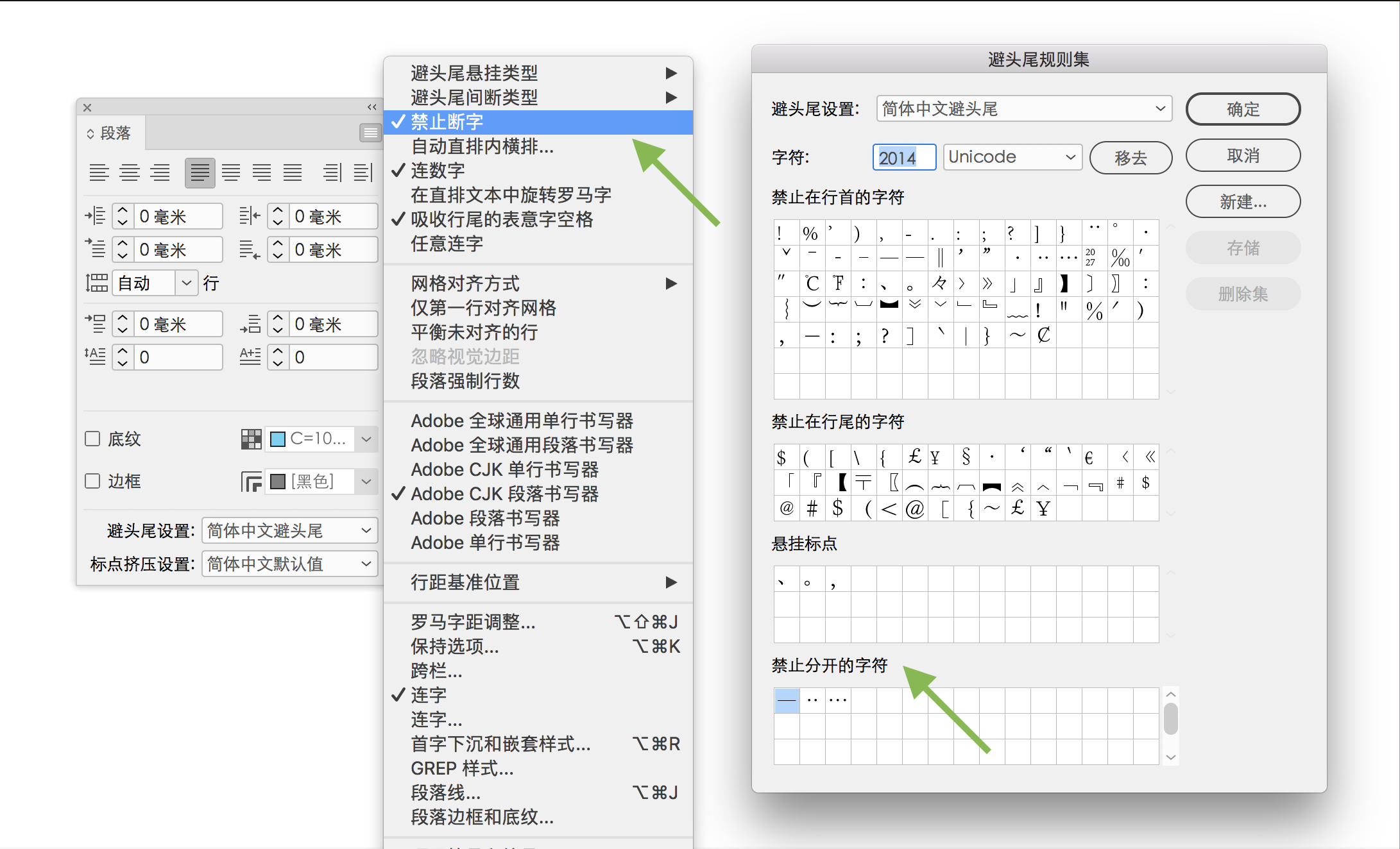
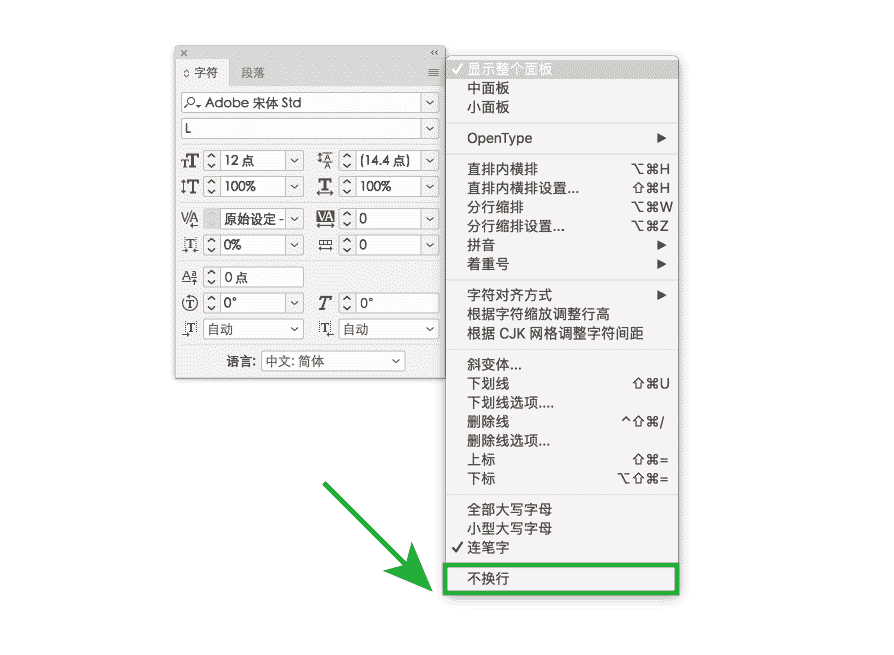
事實上,InDesign 里「字符」面板選項菜單的「不換行」原本是為西文排版準備的。在英文原版里,這個選項菜單寫作 No Break,用戶選擇任意幾個字符,再勾選這個選項之後就可以保證不會在此斷開。顯然這是局部的、手動指定,並不具有普適性。雖然中文破折號,也可以這樣手動選擇後勾選「不換行」,但如果全篇文檔有十幾個破折號,就必須一一手動選擇進行設置,非常麻煩。
而「段落」面板里的「禁止斷字」,則是和「避頭尾規則集」對話框中「禁止分開的字符」定義連動的。也就是說用戶需要先在「禁止分開的字符」定義里添加各種字符定義,然後才能通過勾選「段落」面板里的「禁止斷字」來實現這個功能。好在「禁止斷字」這個功能默認是打開狀態。但是,勾選中「禁止斷字」卻在避頭尾設置選「無」,軟件失去了字符定義參照,同樣不起作用。
這個「禁止斷字」是 Adobe 為東亞排版而設置的功能,或者應該嚴格地說,這是為了實現日本 JIS X 4051「分離禁止」處理而設置的功能。翻閱 JIS X 4051 原文可以知道,日文排版所謂「分離禁止」是指字符之間不能斷開,且在標點擠壓等間距調整處理時也不被拉開;具體對象有破折號、省略號、「連數字」、西文單詞等。顯然,與「不換行」單純功能相比,這個需求更突出了「在標點擠壓等各種間距調整處理時也不被拉開」的重要性。如果忘記定義,破折號的兩個字符之間在兩端對齊調整字距時依舊有被斷開的危險。因此,即使決定要採用「寬式」風格不避頭尾,在「避頭尾規則集」對話框上方里的「禁止在行首的字符」里刪除掉相關字符,但依然要記着把所有這些相關字符(為了保險,建議把 U+2014、U+2015、U+2500 等等)都寫入底部「禁止分開的字符」定義表裡,保證「避中間」,不至於連用時從中間斷開。
網頁與電子書的尷尬
網頁和電子書籍的排版的基礎都是使用 HTML+CSS 來實現,但同樣也需要從字符、字體、排版引擎等幾個層面分別考慮破折號問題。對於字符碼位,首先應該要留意 Unicode 標準附件第十四號《Unicode 斷行算法》(UAX14) 中對幾個相關字符的默認定義:
- 對於目前最常用使用的「—」(
U+2014 EM DASH),其斷行屬性為 B2 類,換行動作是 B/A/XP,即「前可斷行、後可斷行、但中間不能斷開」,也就是說默認動作是「不避頭、不避尾,但是避中間」; - 若使用「―」(
U+2015 HORIZONTAL BAR) 這個字符,其斷行屬性為 AI 類,即「不明確」,換行行為要取決於具體情況,因此要慎重。但由於其東亞寬度屬性 (UAX11) 也屬於 A 類「不明確」,在沒有明確語言標籤、文本識別、數據源等可靠參照時,會被處理 Narrow「窄字符」和西文字母一樣具有 XP(中間不斷開)的動作; - 如使用「⸺」(
U+2E3A TWO EM DASH)與「⸻」U+2E3B THREE EM DASH,這兩個字符斷行屬性與U+2014 EM DASH同樣是 B2 類,因此默認動作是「不避頭、不避尾,但是避中間」。
開發者應該決定使用正確的碼位,並了解這些字符的默認動作,然後再根據實際需要來決定是否進行額外的操作。比如目前最常見的做法是使用兩個U+2014 EM DASH,其默認其實就是「寬式」避頭尾原則,這是比較務實的做法。但如果要執行「嚴式」避頭尾,則需要結合其他方法自行定義。
當然,從 CSS 定義字體的工作來說,破折號與其他標點一樣,需要從系統字體的回落機制與是否定義網絡字體等角度進行決策。然而,很多網頁設計師為了實現「中西混排」,依照桌面排版「複合字體」的思路,按照目前 CSS 字體的回落機制,在 font-familiy 里將西文字體擺在中文字體前面,保證西文用西文字體顯示。這種方式會影響數個「中西共用」的標點符號,包括蝌蚪引號和破折號在內的一些中文標點會優先按照西文字體中的字形顯示,導致位置下沉或者斷開等各種問題。
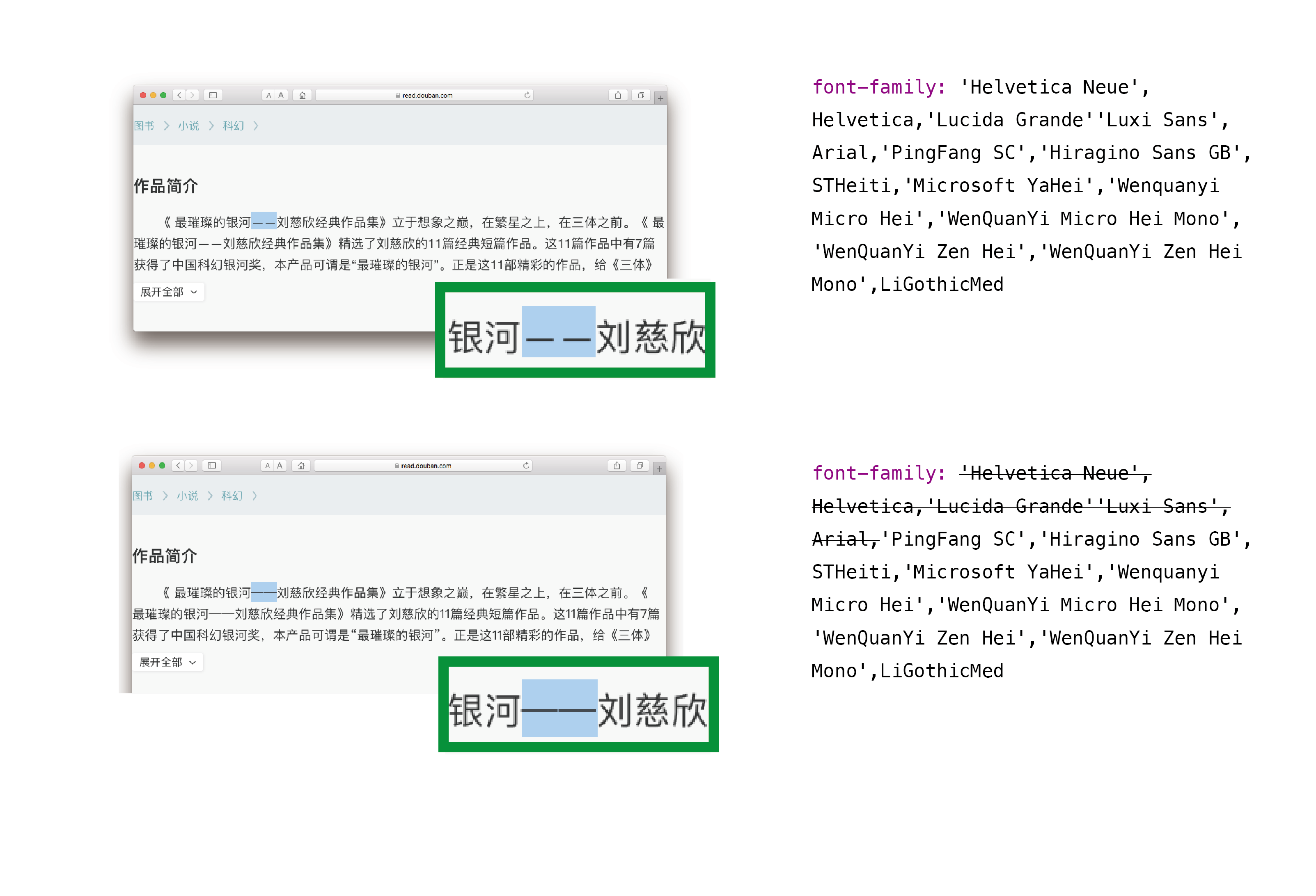
要解決這個問題有很多方法,比如可以通過額外定義 Unicode 碼位範圍分別定義字體,或者直接使用某款系統的中文字體或者一個已預先搭配好中西字形的字體,有能力的網站甚至自行封裝一個網絡字體,等等方法都能解決。如果使用思源這樣支持 locl 標籤的字體,還應該在合適的地方(比如 <lang> 語言標籤)進行語言聲明。最終效果可以通過比對實際調用的字形來分析解決,需要多嘗試,畢竟選擇一個靠譜的字體是進行正確排版的第一步。
小結
破折號這一現代中文裡常見的標點符號,經常由於各種原因無法被正確地輸入、顯示。本文從最基本的需求出發,指出破折號原本應該是一個符號而不是兩個字符的拼接,中間不能斷開,位置要位於漢字字框的上下中央,雖然佔兩格但其長度最好不要撐滿。在目前的實際操作中,已多用拼接兩個「—」(U+2014 EM DASH) 字符來表示破折號,但移動設備系統的輸入法的界面還有待改善,以便以更友好的方式讓用戶輸入。而字庫廠商則應該學習 Adobe 製作「思源」系列字體的第一步做法,提供更為精準完美的「佔兩格卻不撐滿」的字形,積極採用 OpenType 的 GSUB 特性讓用戶在輸入兩個連續 U+2014 EM DASH 時能自動替換成正確的字形。而在排版方面,最重要的應該是保持破折號不被斷開,這一點無論是在字處理軟件還是專業平面設計軟件都有相應的設置,並且在實務操作上應該考慮周全一些,對相關的若干個字符都進行統一定義,保證沒有漏網之魚。至於破折號的避頭尾問題,中國目前的推薦國標根本就沒有提及,而實際上「寬式」的「不避頭尾」原則已經足夠,畢竟避頭尾規則過於嚴格容易導致調整量加劇,因此在排版風格決策的時候要謹慎處理。而網頁和電子書排版時,要特別注意 CSS 的字體回落機制對顯示造成的影響,針對實際效果在各個環境下進行調試。
不要小看破折號這樣一根橫杠,其牽涉的這些問題,其實都是當代中文字體排印發展歷史和現狀的一個折射。不吃透中文內在的實際需求而生搬硬套西文的符號,會導致扭曲的實作,一步錯而步步錯,之後會為向後兼容和迂迴處理而付出更慘重的代價。而且,字體排印從需求、碼位、輸入法、字庫、排版引擎到顯示印刷的最終效果,每個環節都會牽一髮而動全身。正因如此,才需要我們從整體的角度全盤考慮才能把問題解決得更透徹。
其實不僅是破折號,現代中文排版里必須的連接號、省略號,以及在網絡上吵得沸沸揚揚的直角引號與蝌蚪引號之爭,其背後都有各種各樣類似的問題,本文選擇破折號為闡述對象,是因為破折號彙集了各種問題於一身。以破折號為切入口理清各種問題,這些經驗對其他各種「問題標點」都會有借鑒意義。只有這樣才能整體提高標點符號的可用性,為實現一個有邏輯的中文排版打好基礎。
註:
- 《芝加哥風格手冊》(The Chicago Manual of Style,第 17 版)第 6.83 節指出:「按英國用法,在長文中,比起 em dash 通常更偏好使用一個 en dash(前後加空格);也有一些非英國出版社追隨這種方法。」而在《新牛津風格手冊》(New Oxford Style Manual, 2016 版)第 4.11.1 節中也指出「很多英國出版社用 en rule 前後加空格作為插入用的 dash 符號,但是牛津風格和大部分美國出版社使用 em rule。」↩︎
鳴謝
感謝柳東原先生對本文的協助
參考書目與資料
- 於光宗.排版與校對規範(第二版).北京:印刷工業出版社,2011.
- GB/T 15834-2011 《標點符號用法》
- JIS X 4051:2004 『日本語文書の組版方法』
- The University of Chicago Press, The Chicago Manual of Manual of Style, 17th Edition, 2017
- Oxford University Press, New Oxford Style Manual, 2016

{kind=link}
3 個Trackbacks
[…] 破折號到底是什麼? […]
[…] 〈不離不棄的破折號〉,「孔雀計劃」中關於破折號的文章 […]
[…] The Type — 文字 / 設計 / 文化 » 不離不棄的破折號 […]