
「孔雀计划:中文字体排印的思路」系列倡导从中文出发、以中文的思维方式讨论中文排版。从本文起将重点分析几个中文的特殊标点符号。希望读者可以结合本系列之前关于「挤挤总是有的」「避头尾」等几项内容一起来阅读分析。
2016 年 7 月「知乎 LIVE」新上线,而本站作者、多语言字体技术开发者梁海随即在其知乎专栏里发布了一篇名为《破折号好难啊!破折号怎么这么难!》的文章。他在文章里附上了 2016 年 7 月 8 日在推特上发的截图,并对 1024 场次「知乎 LIVE」中使用的 907 个破折号进行了统计,结果发现居然有 11 种用法,情况之复杂以致于他说「嗯……我懒得分析了。」既然如此,笔者就接这一棒,为大家分析一下为什么破折号这么难。
目录
破折号到底是什么?
与其他常用标点符号一样,破折号也是在十九世纪末二十世纪初现代中文新式标点符号形成过程中从西文引入的一个符号,与其关系最为密切的,当属西文里的半角连接号 en dash (–) 和全角连接号 em dash (—)。这其中具体的演变历史甚为复杂,远超本文所能论述的范围,但基本上可以笼统地说,由于汉字面积比西文大得多,在上世纪初将西文符号引入中文时,都按「半身」「全身」的倍数关系,将包括空格在内的很多符号放大了一倍。这样不仅与方块汉字更搭配,而且,拉长后的破折号还能预防横排时与汉字数字「一」、直排时与「丨」(竖)混淆。于是一个「占两个字宽」的符号就这样逐渐在现代中文里稳定下来。经过岁月变迁,随着中文标点符号的格式与使用方法日趋规范,时到今日,连小学的语文教学里都会说,破折号应该是「占两格的一条横杠」。目前,在中华人民共和国的推荐国标 GB/T 15834-2011《标点符号用法》里,相关记述如下:
4.10 破折号
4.10.1 定义:标号的一种,标示语段中的某些成分的注释、补充说明或语音、意义的变化。
4.10.2 形式:破折号的形式是“——”
(中略)
5.1.4 破折号标在相应项目之间,占两个字位置,上下居中,不能中间断开分处上行之末和下行之首。
和连接号傻傻分不清楚
但正是因为「一条横杠」的外观与另外一个标点符号「连接号」酷似,导致很多人「傻傻分不清楚」这两个标点符号。我们再来看看同一份国标对「连接号」的相关记述:
4.13 连接号
4.13.1 定义:标号的一种,标示某些相关联成分之间的连接。
4.13.2 形式:连接号的形式有短横线“–”、一字线“—”和浪纹线“〜”三种
5.1.6 连接号中的短横线比汉字“一”略短,占半个字位置;一字线比汉字“一”略长,占一个字位置;浪纹线占一个字位置。连接号上下居中,不出现在一行之首。
其实从用法上说,二者差别可以简述为「断」与「连」,即破折号强调「断」,比如插入说明、转变话题、引出下文、声音延长、话语中断等;而连接号强调「连」,表示连接或者起止。只要牢记这个原则,在用法上应该不难区别。
然而在形态方面,对比国标 5.1.4 与 5.1.6 的描述可知,除了「浪纹线」以外,破折号与连接号的「短横线」「一字线」的位置都是「上下居中」,因此这几个符号只能通过长度进行判断。从实际使用的角度来说,这增大了区别这几个符号的难度;而从设计的角度来说,这也突显了绘制这几个符号时「长度」的重要性。
一个符号还是两个符号?
其实,冷静地从零开始再次认真阅读国标中的定义,我们不难发现,从正确的逻辑上说,破折号是一个符号占「两个字位置」,而不是将两个字符合成一个。
虽然「占两个字宽的一个字符」听起来很怪异,但在传统的铅字排版里完全不成问题。现代金属活字在欧洲诞生时,由于主要是铸造「比例宽度」的西文字母,各个铅活字的字身本来就有各不相同的字宽。对于破折号,只要直接铸到一个「占两个字宽」的「两倍」字身上即可(有时也沿用日文称「倍角」)。反而是到了近现代,打字机的字体都是等宽,而早期计算机更是无法处理「占两个字宽的一个字符」,因此只好采用变通办法,通过重复两个全角横杠来代替实现。这并不是设计中文打字时一拍脑袋的决定,而是模仿了英文打字里做法。早期一些西文打字机为了节约键位,连数字 1 和字母 I 都能兼用一个键位,而用两个连字符代替西文 dash 的做法已经还算是还原度很高了。很明显,这是当时在技术限制下的一种变通方法,从理论上和逻辑上说并不能算完全正确,而到现在更不需要照搬。

因此,如果要提破折号的需求,首先它必须是一条横杠,绝对不能断成两条。这原本是一条很基本的要求,但目前在很多实作里往往做不到,比如读者此时此刻的阅读环境下看到这篇文章里的破折号也许就是断开的。而正是因为用两个符号拼接才导致了各种问题,比如被显示成断开的两条横杠,甚至在换行时被分成两截、前一半在前行行末、后一半在后行行首等等原本不应该出现的错误。如何解决这个问题,将在下文展开讨论。
不单纯是断开问题
破折号的第二个需求是位置问题。上述国标指出,中文的破折号、连接号以及各种括弧、省略号都应该「上下居中」,也就是在正方形字框里垂直方向的正中央。这与西文里的这类标点不同。由于西文标点的设计目的是要与具有升部和降部的小写字母搭配,因此西文里的这类横杠类标点的位置往往比中文标点要低一些,比如西文连字符用在中文里就感觉位置下沉,而西文的两条全角连接号即使能连起来,位置也不在汉字字框的上下中央。这其实涉及到中西文混排的问题,将在下文展开说明,但单就中文标点的来说,需求其实很简单,就是必须要上下居中。

第三个需求,也是被很多人忽视的一点,是破折号的长度问题。从一个追求完美的设计师的角度来看,尽管破折号要求占两个字宽,但是最好不要顶格。也就是说,这条横杠最好不要左右撑满字符框,而是要留有一些喘息的空间。在设计汉字时,除了需要一个虚拟字身的「字框」以外还有一个「字面框」,每个汉字不可能所有笔画都把字框撑满,否则「原始字距」变成零之后,在以「密排」为基础的排版里相邻汉字全部会粘到一起。汉字如此,标点符号设计也是如此。尽管破折号是一条横杠,但最好在其两端留下一些空间。当破折号前后紧跟汉字「一」时,比如遇到「表里如一——一一分辨」这样的句子,是否能让读者看清楚就显得非常重要了。「活字」之所以「活」,是因为它能与各种不同的字搭配,必须要考虑到一些特殊情况。
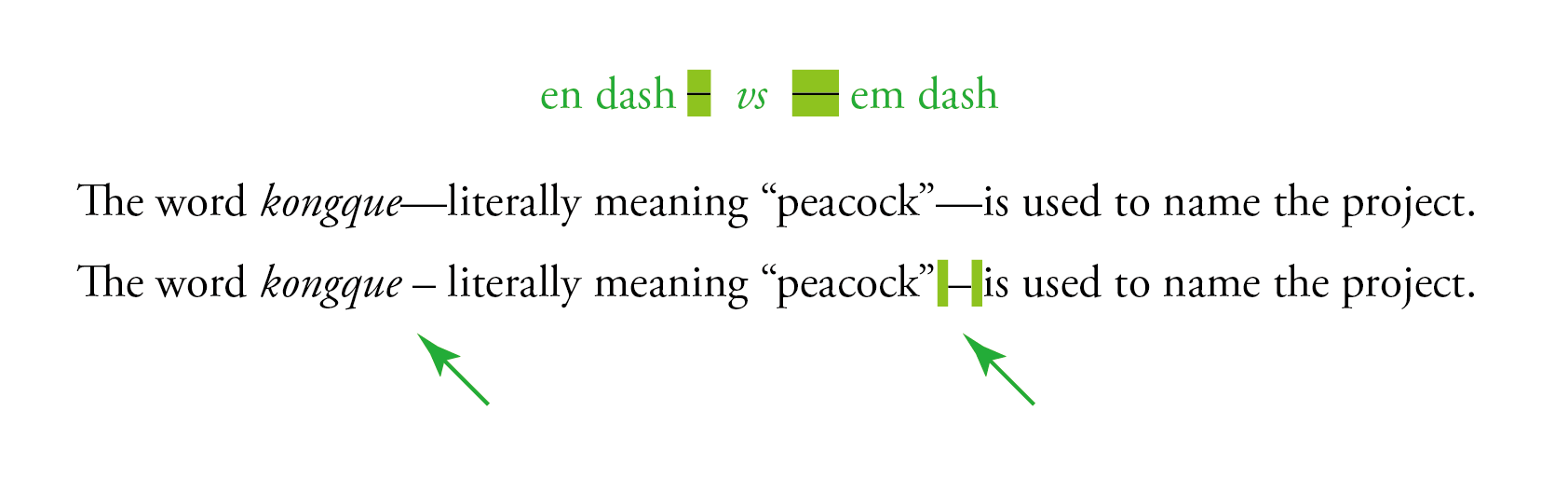
这条需求其实和英式排版里 en dash 的用法有异曲同工之妙。美国「芝加哥风格」与英国「牛津风格」里都写到1,在长文章排版里,很多英国出版社(但牛津出版社本身除外)偏好在本该使用 em dash 的地方改用前后加空格的 en dash 的方式,这样可以让读者在视觉上感觉横杠不致于贴着文字太近。
当然,除此之外,破折号在设计上还有其他需要考虑的要素,比如破折号这条横杠在不同字重、字号下的粗细变化问题。汉字字体中粗细问题涉及到笔画笔形、文本灰度等诸多要素,根据字体的设计理念有不同处理方法,不能做硬性需求,只能靠设计师在设计上进行定夺,可以做进一步讨论。而上述的提到的三点,则应该是作为基本要求需要实现的。但目前的情况是,这些需求在具体实作中都会遇到从输入到显示、从字库到排版各个层面的问题,本文接下来就开始仔细分析。
破折号的码位
如前所述,金属活字时代的铸字厂可以用不同字身,分别铸造不同大小、长短的铅字供印刷排印时区分使用;可是到了数码时代需要键盘输入时就一头雾水了:上述国标并没有给出明确的码位,计算机编码制定人员与输入法、字库厂商对该符号分别做了不同解读,导致各种实作非常混乱。而作为用户,很多电子设备使用者也不在意细微的区别,也没有认真学习输入法,输入时随便挑一个长得像的符号套用。更令人头疼的是,互联网通讯便利反而加速了错误用法的传播,看多了错误的用法,反而觉得习以为常、见怪不怪了。
在数码时代我们首先需要的,是在字符编码层面(如 Unicode)为中文的破折号找到一个正确的码位。问题是,这个码位在哪儿?
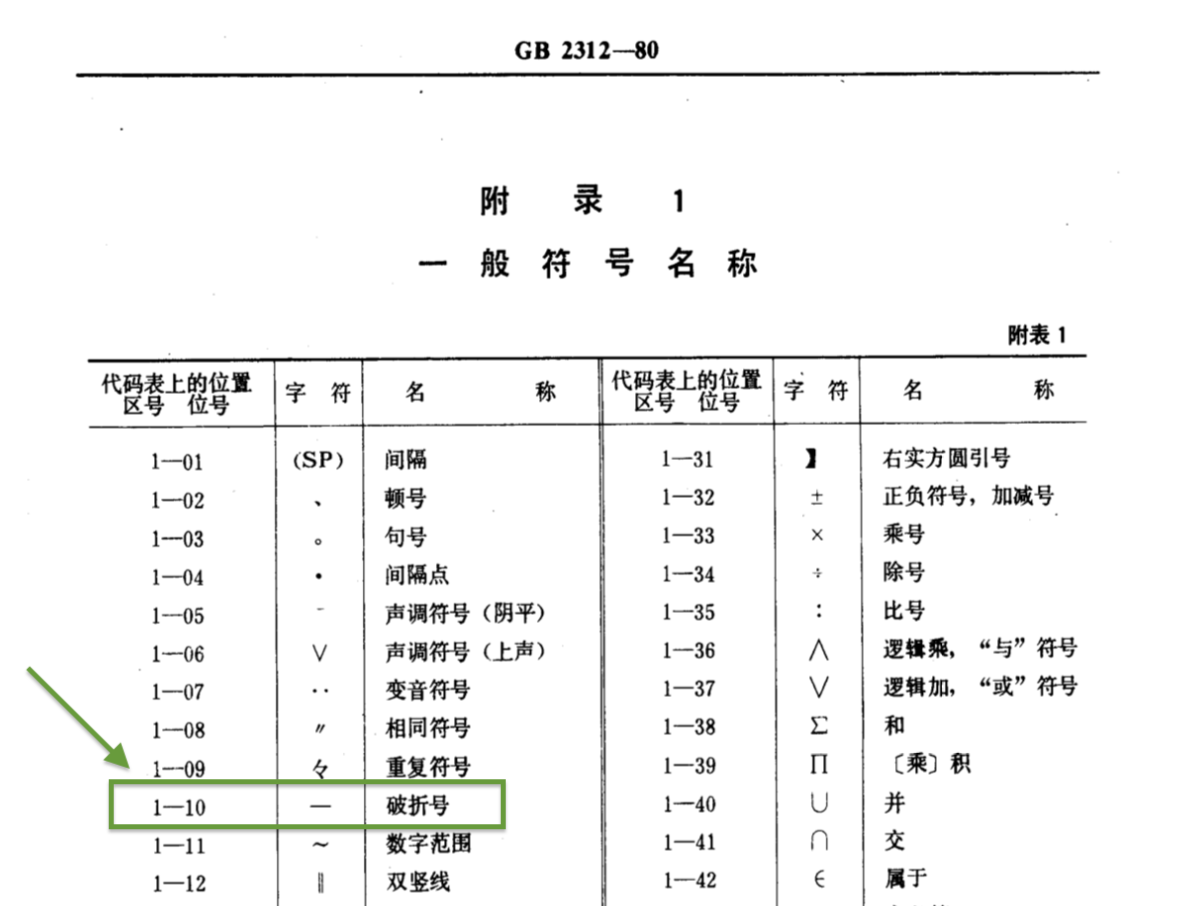
东亚各地区的标准化机构在上世纪七八十年代陆续为各自地区的字符制作了字符集编码,比如日本工业标准有 1978 年发布的 JIS C 6226(现已改为 JIS X 0208)、中国大陆国标有 1980 年发布的 GB-2312、港台还有 1983 年发布的大五码(BIG5)等等。查阅中文编码初创期的资料可以发现,在 1980 年版的 GB-2312 里,1-10 区位上的符号名称即是「破折号」。而事实上这个 GB 标准几乎是照搬了日本 JIS C 6226 的结构和顺序,这其实为后来 Unicode 映射错误埋下的隐患。但最重要的是,这个符号虽然名叫破折号,但明显是一个只有一个汉字字宽、所谓「全角」的字符。出于早期的计算机功能限制,在编码当初就已经决定要用这样一个所谓的全角符号去拼接破折号的做法。
Unicode 这个大杂烩
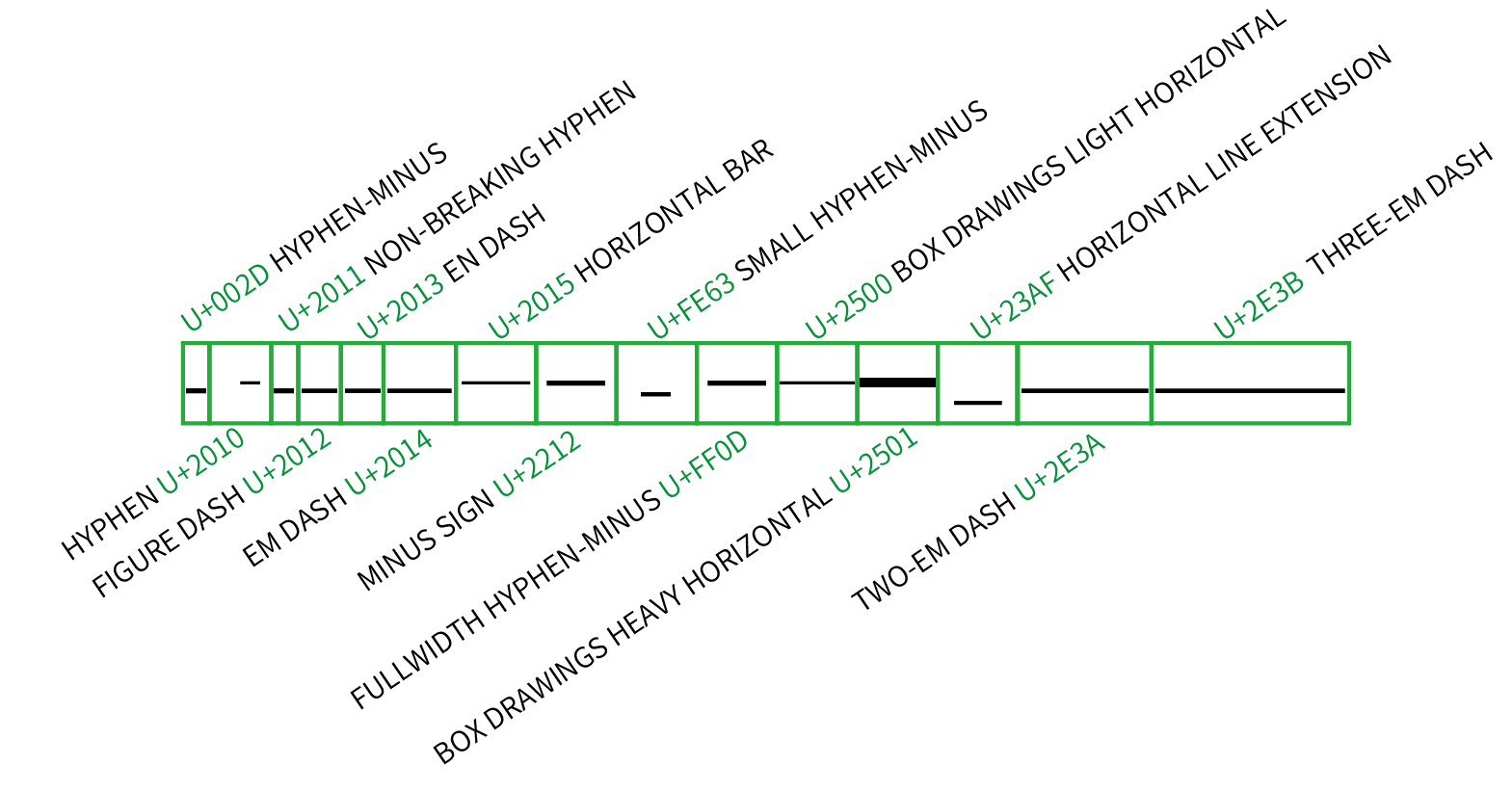
经过万「码」奔腾、乱码横行的时代之后,字符的编码技术逐渐向 Unicode 靠拢。由于要收录全世界各种书写系统的字符,目前 Unicode 里已经定义了大量与连接号和破折号相关的横杠字符。比如在西文里,除了常见的连字符「-」、en dash「–」、em dash「—」之外,有数字连接号(Figure dash)「‒」等等。西文字体排印里会用数字连接号分隔数字,比如 130-1234‒5678 这样的电话号码里,其宽度与普通数字搭配,但不能表示范围(因为表示范围在英文要用 en dash)。这些在精细的字体排印实作里都会严格区分,而在一般运用上往往会被不明真相的用户混做一团。
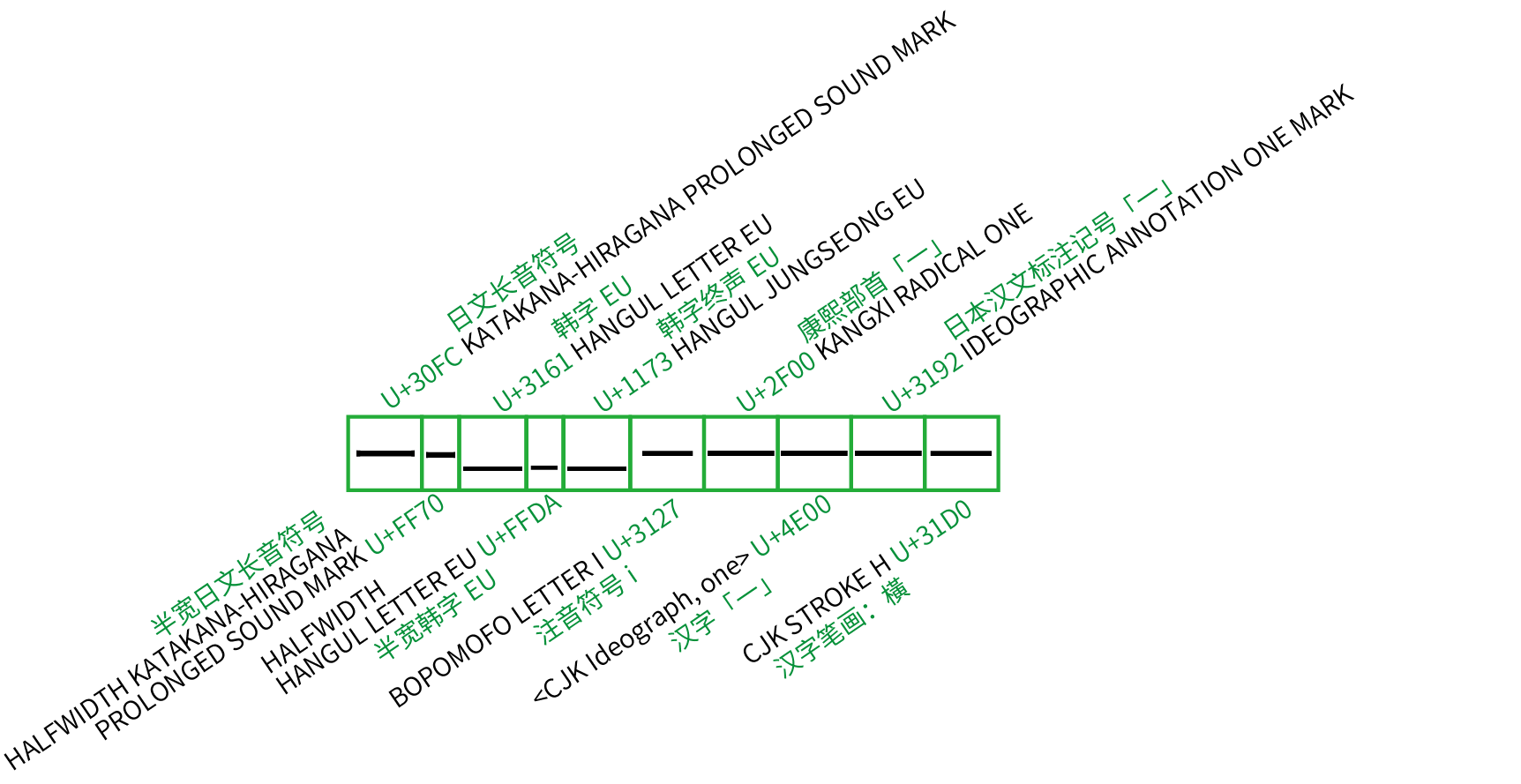
如果再放眼到西文以外的区块,「长得像一条横杠」的字符更是多达几十个:汉字「一」、韩字 eu「ㅡ」、日文长音符「ー」、制表符「─」甚至表情符号的减号「➖」,通过黑体、无衬线体这类字体渲染之后都长得非常雷同,让用户莫衷一是。偷懒的用户可以随便在符号列表里挑一个长得像的蒙混过关,拿日文长音符充当中文破折号这样的尴尬排版也屡见不鲜。
2014 还是 2015,这是个大问题
从用法来说,Unicode 里与破折号关系最近的似乎应该是「全角连接号」 U+2014 EM DASH,这也是目前大部分实作的「事实标准」。显然,这个码位要表示的原本是一个西文的标点,拿到中文里用首先会导致中西文标点共用同一个码位的问题,实际显示效果往往会根据不同字体而异。正如前文所说,一般的西文字体里由于要与拉丁小写字母配套设计,横杠位置会水平偏下,显然不符合中文破折号的需求。当然,中文字体厂商则会在这同样的码位上放上一个水平居中的横杠,用户必须选择中文字体才能正常显示。这种中西文标点共用码位的情况并不仅限于破折号,它与蝌蚪引号(“”)等符号一样,总是会在中西混排时引发很多麻烦,在此就不多展开了。
再来看看这个码位旁边的那个叫「横杠」U+2015 horizontal bar 的字符。在《Unicode 核心标准》第 6.1 章里明确写到它「在一些字体排印风格里用于引出一段引文」,而码表里也明确注明 2015 HORIZONTAL BAR = QUOTATION DASH,这个用法也是中文破折号的用法之一,从用途上说,这个码位也可以拿来用作破折号。
另外,如果重视上述破折号需求二的位置问题,有人会干脆用「制表符细横线」U+2500 BOX DRAWINGS LIGHT HORIZONTAL 这个字符。很明显,由于这个字符是「制表符」,因此无论什么字体,其位置肯定是水平居中,而且肯定还是连着的,不管语义是否正确,至少从形式上一了百了地解决了一些问题。

另一方面,从各地标准转换到 Unicode 时还有过一些阵痛。东亚各地区的编码用在各自的系统里并没有问题,但是后来 Unicode 出现之后,需要将本地字符与 Unicode 规整、映射,于是各种各样的问题层出不穷,其中最典型的例子就是「CJK 统一汉字」的认同 (unification),而破折号也不幸陷入其中。
作为东亚字符编码的先驱,JIS 本身曾经有过一段乌龙。JIS X 0208 及 JIS X 0213 字符集在 1 面 1 区 29 点里安排了一个「连接号(全角)」,并定义其在 Unicode 的对应名称为 EM DASH。按照这个名称,理论上就应该是 Unicode 里的 U+2014。然而后来的 JIS X 0213:2000 却错误地将这个符号映射到了 U+2015,直到 2001 年 5 月才发布《勘误表》急忙订正回来,直到后来 2004 年 JIS X 0213 修订的时候才终于回到所谓正确的 U+2014,风波告一段落。
无独有偶,Unicode 联盟早年在其 FTP 网站上提供的「非规范」信息里也曾把 Shift_JIS 中 0x815C「连接号(全角)」映射到了 Unicode 的 U+2015 码位上。虽然目前这个文件已经被官方声明过期,但使用这个实作的程序时到今日依然存在。微软公司在 Windows XP 使用的代码页 CP932 里也保留了同样的 Unicode 映射。而苹果公司针对 Shift_JIS 的 MacJapanese 编码以及微软 Windows Vista 之后的 CP932 则已经改回到 U+2014 上。
中国的情况也是如此。在 1993 年 12 月 6 日由 Unicode 技术委员会(UTC)提供、 Glenn Adams 和 John Jenkins 制作的《GB 2312 映射表》中 GB2312.TXT 文件里,就将 GB2312-1980 的 1 区 10 位的字符(字节序 0xA1AA)指向了 Unicode U+2015 HORIZONTAL BAR,虽然该文件已于 2011 年由官方弃用,但影响依旧很大。当然,Unicode 在其后的发布的 GBK 与 GB1830 子集的映射都已经改为 U+2014 EM DASH 码位。
而厂商方面,微软公司使用的简体中文代码页 CP936 的最初版本也是映射到了 U+2015,后来在 Windows 95 里将 GB 2312-80 扩展成 GBK 时,将其映射改到了 U+2014。但是,作为历史遗留痕迹,翻阅微软的资料即可发现,微软代码页 20936(即简体中文 GB2312-80)和 10008(即简体中文(Mac))里的映射依旧是 U+2015。微软的文档里清楚地记载了变更:
/* GBK and GB2312 map differently in few code points that are listed below:
* gb2312 gbk
* A1A4 U+30FB KATAKANA MIDDLE DOT U+00B7 MIDDLE DOT
* A1AA U+2015 HORIZONTAL BAR U+2014 EM DASH
* A844 undefined U+2015 HORIZONTAL BAR
*/
而在苹果公司的《简体中文代码映射表》里,也记载了这些变化:(笔者译自 CHINESIMP.TXT 2002 年版)
2. 基本 EUC-CN 字符映射
出于以下原因,对一些非汉字的映射从 UTC 映射做了修改,
– 为了更好地与中国标准化组织 GBK 映射保持一致(GBK 应该包含所有 GB 2312 字符)
(略)
从 n00 版到 n05 版的变更:
A. 为配合 GBK 映射
- 将
0xA1A4映射从U+30FB KATAKANA MIDDLE DOT变为U+00B7 MIDDLE DOT- 将
0xA1AA映射从U+2015 HORIZONTAL BAR变为U+2014 EM DASH(下略)
虽然映射关系已改,但是 php-5.6、ActivePerl-5.20、Java 1.7、Python 3.4 依旧使用老版本将破折号映射到 Unicode 的 U+2015 码位上,这些老版本的影响还远远没有消失,包括微软 Word 在内的应用软件,都多多少少会不经意地暴露出一些问题,具体放到下述章节讨论。
说好的占两格呢
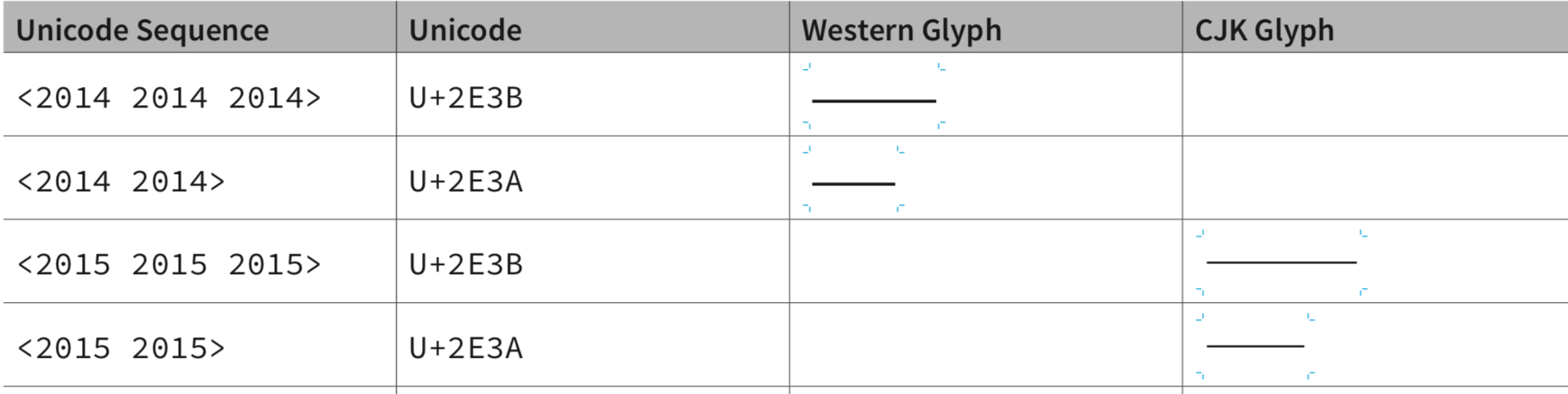
其实,西文的字体排印也存在多个宽度的横杠符号,随着后来计算机性能的提高和文字编码工作的深入,这些符号也相继被收入到 Unicode 里,比如我们可以看到在 U+2E00 – U+2E7F 的「增补标点符号」 (Supplemental Punctuation) 区块里就有 U+2E3A TWO EM DASH(两倍接连号,即「⸺」) 和 U+2E3B THREE EM DASH(三倍接连号,即「⸻」)。
既然中文破折号是一个占两个字宽的符号,那么选用 U+2E3A TWO EM DASH 似乎应该是合情合理的一个选择。然而,Unicode 里最符合逻辑的码位并不一定是最常用的。但这个码位来的太晚,早年打字的习惯已经无法修改,从中国大陆绝大多数的软件实作以及用户习惯并没有用 U+2E3A TWO EM DASH 这一个字符,而是依旧采用两个映射到 U+2014 EM DASH 拼接成一个破折号。显而易见,这不仅无法满足上述的破折号第一需求,而且还为断开等问题留下了后患。在日常生活中,这样的实作唯一一个好处似乎是,歪打正着地可以让用户可以方便输入中文连接号的「一字线」。包括笔者在内的用户,有时候在中文状态下无法方便地输入「一字线」,所以干脆先打一个破折号,再回头删除一格。
在笔者参与编辑的W3C《中文排版需求》里,为了尊重既成事实,编辑们决定采用折中处理,目前版本的行文如下:
破折号是占两个汉字空间的
U+2E3A TWO-EM DASH[⸺]或U+2014 EM DASH[—]。
破折号怎么输入
无论内部码位怎么变化,对于用户来说,最关心的还是如何方便地输入这个破折号。我们再回到本文开头提到的梁海在知乎专栏《破折号好难啊!破折号怎么难!》一文。在他的统计里,用户实际输入破折号的结果按照顺序排列如下:
- 「——」<
U+2014 EM DASH* 2> - 「--」<
U+FF0D FULLWIDTH HYPHEN-MINUS* 2> - 「–」<
U+002D HYPHEN-MINUS* 2> - 「-」<
U+002D HYPHEN-MINUS> - 「—」<
U+2014 EM DASH> - 「-」<
U+FF0D FULLWIDTH HYPHEN-MINUS> - 「— —」<
U+2014 EM DASH,U+0020 SPACE,U+2014 EM DASH> - 「- -」<
U+002D HYPHEN-MINUS,U+0020 SPACE,U+002D HYPHEN-MINUS> - 「—」<
U+002D HYPHEN-MINUS* 3> - 「ーー」<
U+30FC KATAKANA-HIRAGANA PROLONGED SOUND MARK* 2> - 「————」<
U+2014 EM DASH* 4>
看着普通用户们输入的这些问题多多的破折号,总体来说可以分成以下几类:
一、与连接号混淆,因为破折号本身与中西文连接号本来就很难分清;
二、与其他西文符号混淆,比如用西文 hyphen 类的字符;
三、与其他文种的符号混淆,比如日文里所谓「全角」的长音符号;
四、混用其他符号,比如 7. 愣是在两个字符里面加入了一个空格;
五、把一个符号单用、双连用甚至四连用等等
下面我们就来分析一下用户们在输入破折号时的各种烦恼。
输入法的陷阱
依照目前的事实标准,大部分电脑的中文输入法采用的都是在中文状态下同时按住 Shift 键与减号键,这样会一口气跳出两个「全角连接号」 U+2014 EM DASH拼成一个破折号。仔细想来,这种「按一个键跳两格」的操作还真是有些奇妙。在中文标点符号里,只且仅有破折号和省略号这两个「占两个字宽」的标点能享受这种特权。因此,到底是一个字还是两个字的问题着实让人纠结。

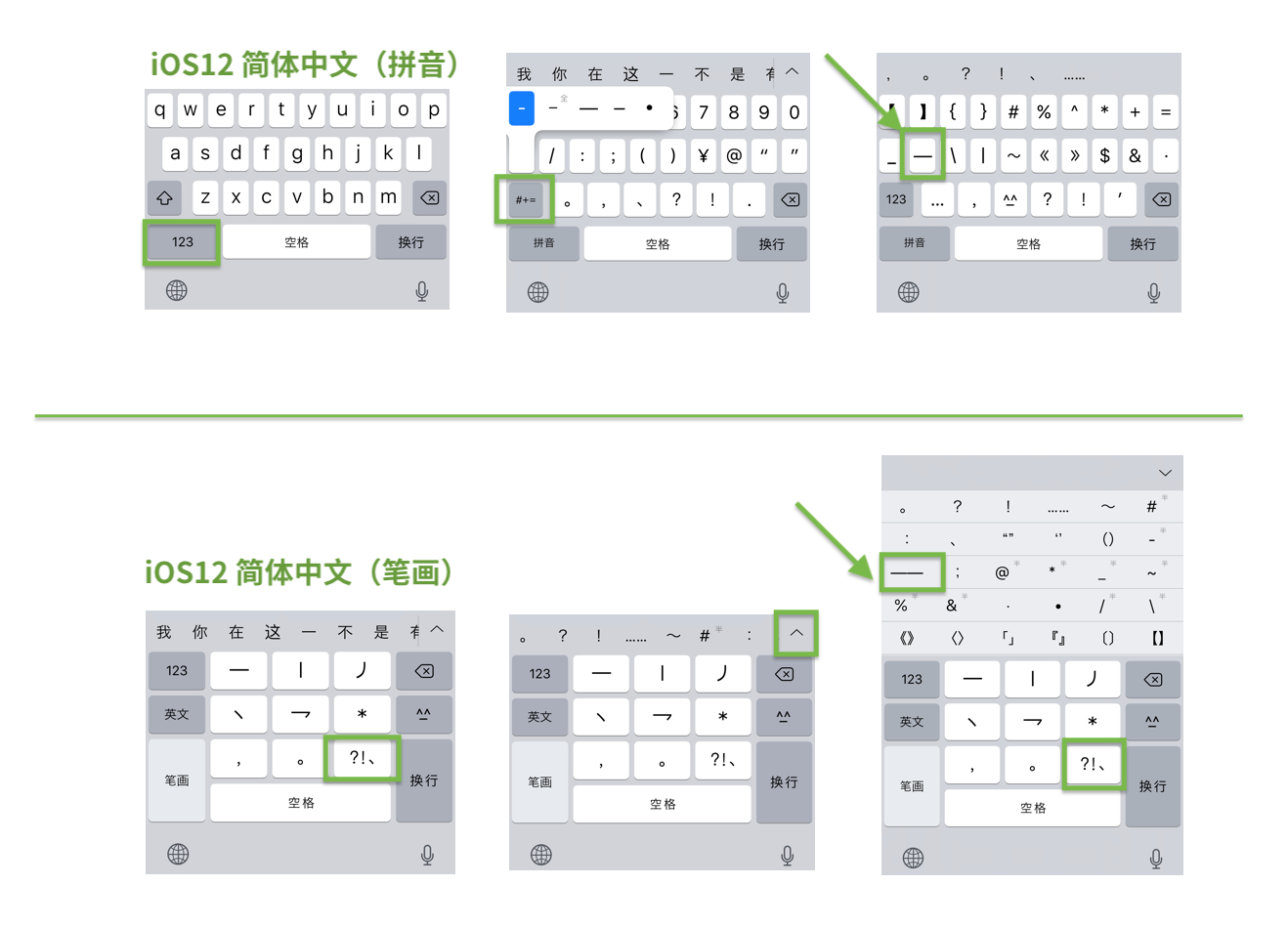
电脑键盘的键位相对稳定,但手机、平板等移动设备并非如此。由于各种触屏设备的软键盘以节约空间为最优先要素,对各种符号的键位进行了改动,而且往往不同厂商的各个机型、系统的各种方法并不统一,人为地加大了标点符号输入的困难。比如在 iOS 简体中文输入法里,「拼音」和「笔画」的界面就很不一样。拼音输入法里,用户需要先按一次空格左边的「123」键进入「数字状态」,再按一次「#+=」键才能找到输入所谓「全角连接号」U+2014 EM DASH 的键位,然后用户需要按两次来组成一个破折号。由于在第一步进入「数字状态」时并没有全角连接号,反而有英文的连字符,这样的用户界面导致很多用户就停在这一步,随便打几个连字符代替了事。如果此时利用长按键盘的小技巧,按「连字符」键调出的更多选项里,各种符号的长短过于近似,一般用户很难选对。相对地,iOS 简体中文的「笔画」输入法的用户体验就非常直接和准确,用户点按「?!、」键即可调出中文标点选项,虽然里面没有破折号,用户也会很自然点击向上箭头拉开选项菜单,而其中备选的破折号、省略号都已经是占两格的形式,括弧也是成对的,用户只需按一次即可完成输入,这个体验明显比「拼音」更为友好,直接而没有误导。
半路杀出的程咬金:拼写自动更正功能
将破折号与连接号混淆已经是常见错误,似乎还「情有可原」,那么为什么用户会三连用甚至四连用呢?从用户心理考虑,看到一个西文连接号(-)放在中文里肯定会觉得的长度不够,下意识地会要连用。一些用户一直抱着「西文符号是半角」的固有概念,觉得打两个「半角」可以凑成一个所谓「全角」,再用两个全角拼成占两格的破折号,于是就连按四下。
这在一些字处理软件里往往可以歪打正着地成功输入破折号,因为有些软件系统有「拼写自动更正」的功能。无论是苹果公司的 macOS 或 iOS,还是微软 Word,都会默认启用「自动更正」,而这个功能往往都会将连续两个西文连字符(hyphen)替换成「全角连接号」的 em dash,即一个 U+2014 (中文版 Word 里称之为「长划线」)。
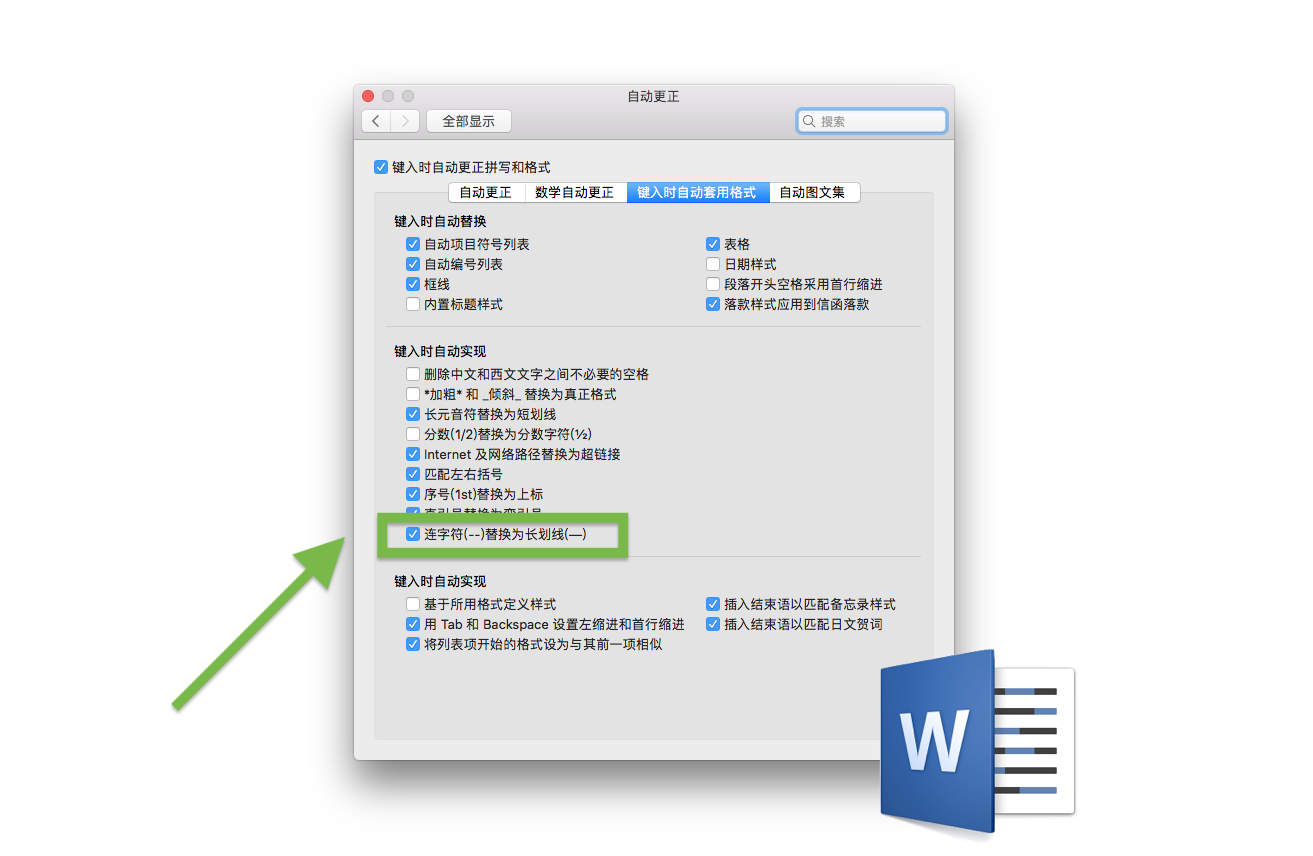
然而,这个体验并不是连续的。一旦脱离了带有自动更正的软件环境,在一些纯文本编辑器下,这类连打就不起作用了。正如本文第一章第二节所述,由于西文打字机用户会打字机替代键位的旧习惯输入西文 dash,因此软件在「自动更正」里对此设计了这样一个方便功能,但显然这并非为中文排版所设。
我们也可以呼吁各种排版引擎考虑增加对中文的需求,但是这个需求是什么、如何实现才合理,需要认真定夺。比如,如果单纯设置将两个 U+2014 自动替换成一个 U+2E3A TWO EM DASH,这依旧需要字库的支持。否则,好不容易换到了 U+2E3A TWO EM DASH 而字库厂商却又没有绘制这个码位的字形,会导致字符无法正常显示,用户就会看到「豆腐」或者干脆什么都没有。退一步来说,如果这样的替换处理不是在文本处理,而是在字体层面利用 OpenType 的 GSUB 特性就解决掉,那么排版引擎方面就要把工作重心转移到「全面支持 OpenType 特性」上了。从这一点我们也可以看出,字体排印处理是环环相扣、相辅相成的,一个环节出问题都会掉链子,而在哪个层级处理问题,需要对整个环节有正确理解的基础上再做判断。
破折号怎么显示
无论用户如何输入,字符最后要正常显示输出,还是要靠字体厂商和排版引擎。早在 2011 年知乎上就有这样一个问题:「目前网上使用的中文破折号普遍存在「中间断开」的问题,应该如何解决?」现在,八九年已经过去,让我们看看现状是否有改善。
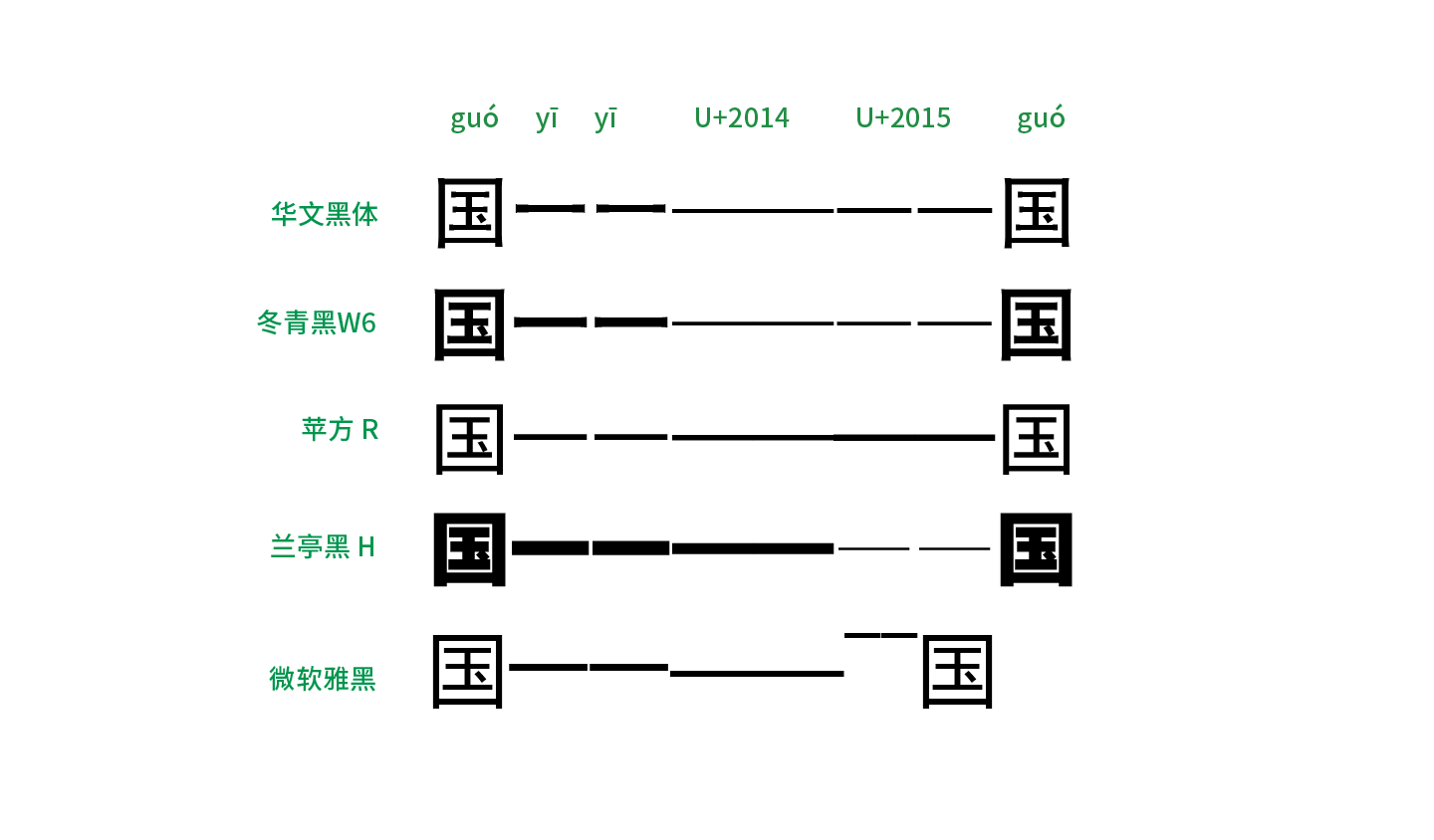
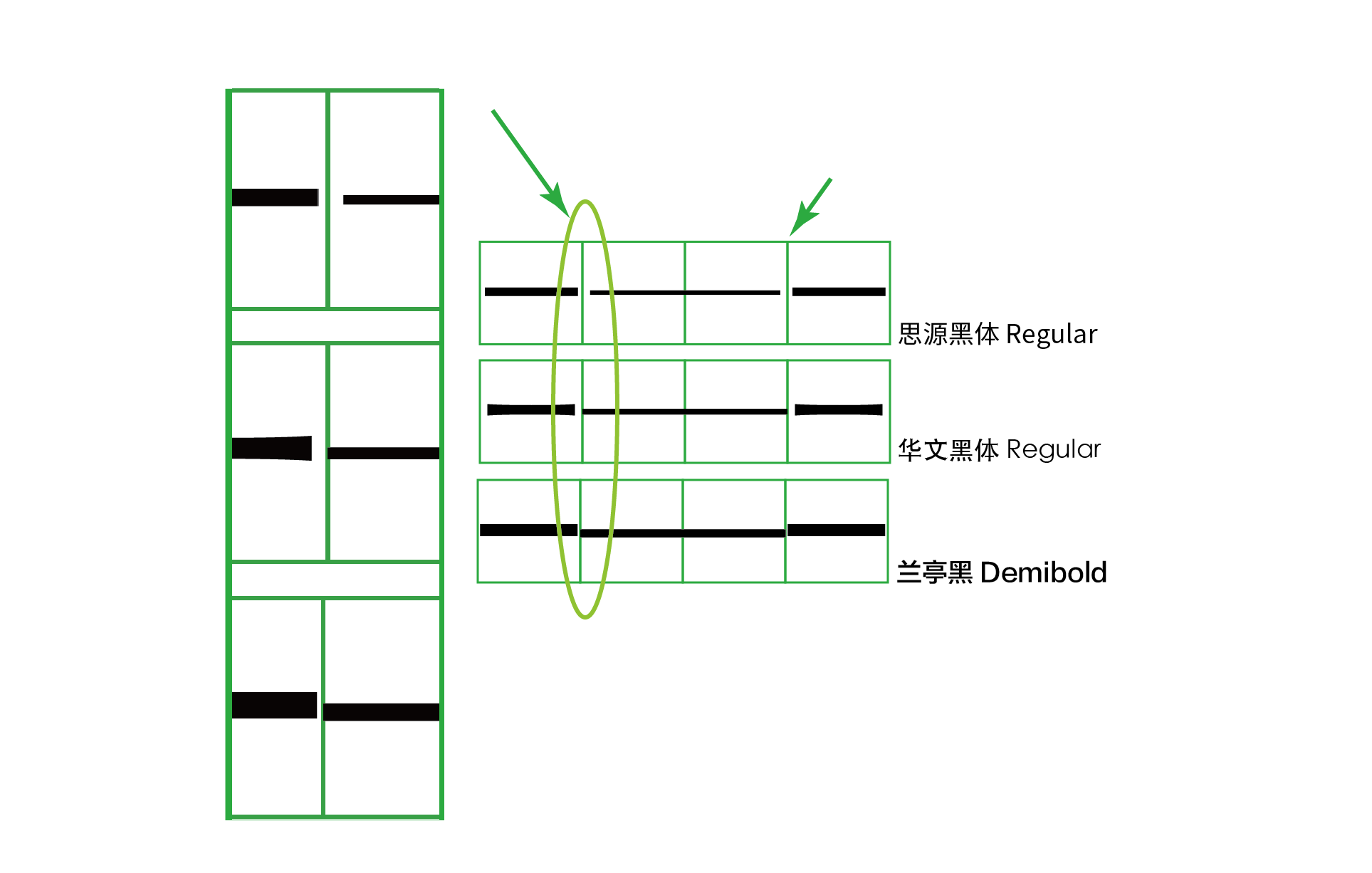
先来看看常用于屏幕显示的黑体。从上图罗列出了一些常见的黑体可以看到,针对目前最常用的 U+2014 EM DASH 这个码位,大部分厂商都将字形制作成位于水平中央、左右撑满的横杠,保证了连用不断开,满足破折号的前两个要求。而对于 U+2015 horizontal bar 这个码位的字形,大部分字体里的字形左右留空,因此两个连用时会断开。只有「苹方」将这两个字符的字形都做成了左右撑满,粘在了一起,但似乎用了不同的粗度加以区分。「华文黑体」这样的老派泛用黑体字库里,汉字「一」、U+2014、U+2015 三者的粗细都不一样,加大了区别度。当然,在现代字库「多字重」的家族展开里,针对「不同字重下的标点粗度是否应该随字重的变化而变化」这个课题,各个厂家有着不同的解答。比如方正「兰亭黑 H」的 U+2014 EM DASH 明显按照 H 字重加粗了,但 U+2015 却依旧非常细。另外,旧版微软雅黑里的符号依然「不走寻常路」,U+2014 的字形不仅位置下沉,两个连用时长度居然还超过两个字宽,而又把 U+2015 horizontal bar 做成上浮横线,实在令人哭笑不得。
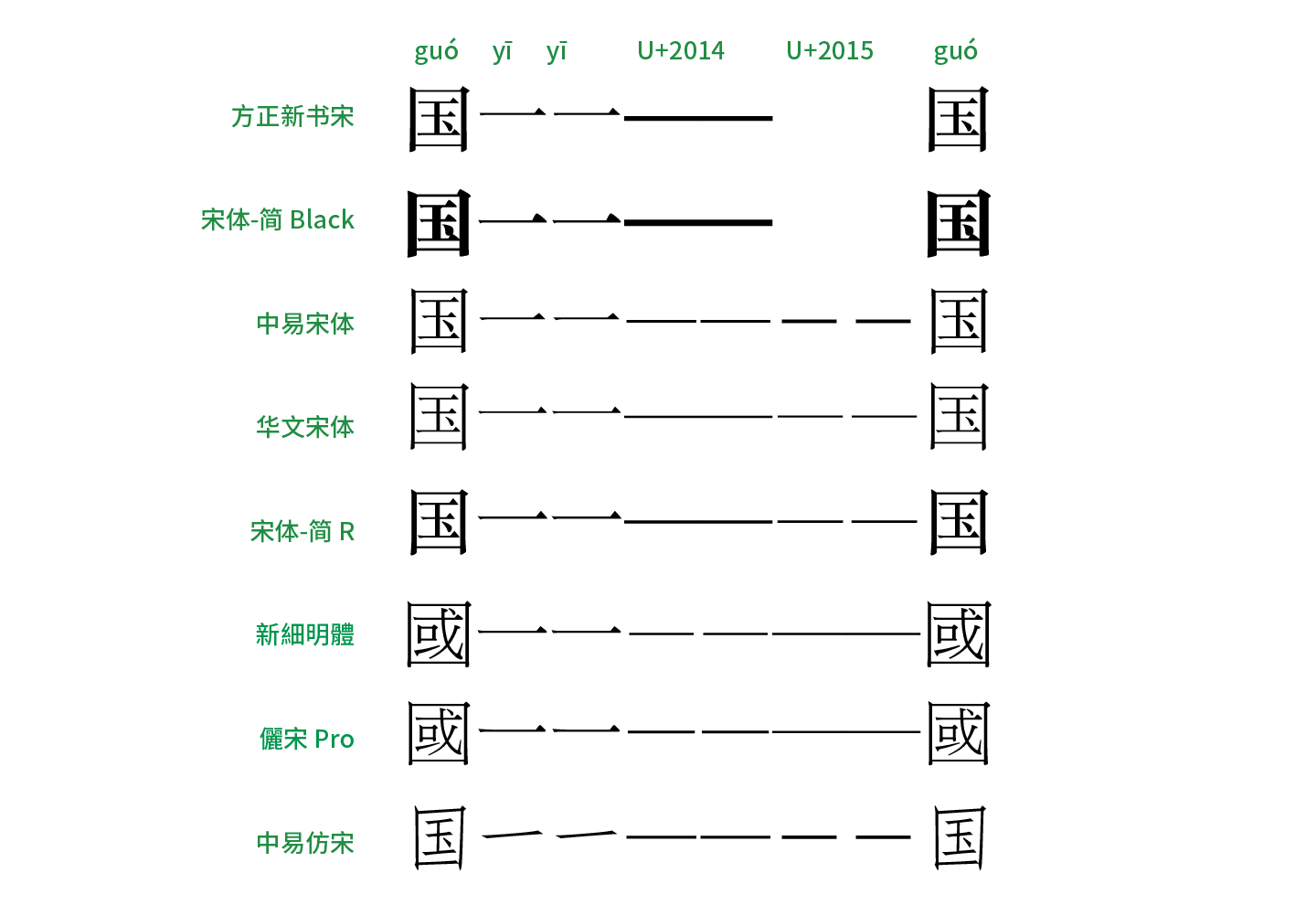
而看看相对多用于正文的宋体、仿宋,在一些旧版字体里,破折号被断开的惨剧依旧在上演。在图中还能看出另外一个规律,即中国大陆简体字库里基本上都会将常用的 U+2014 做成水平中央、左右撑满以保证不会断开,但对于 U+2015 要么是没做、导致缺字,要么是左右留空而断开。而在繁体字库则相反,U+2014 的字形连用时会断开,但是 U+2015 却可以连起来,这明显是上述历史原因以及地区差异造成使用习惯不同而形成的实作。当然,像中易宋体、中易仿宋这样无论如何都接不上的破折号实在令人心痛,对于这类老字库,用户还是避开使用为佳。
然而,针对「两个字符连成一个破折号」的事实标准,一些新字体进行了新的尝试。2015 年 Adobe 公司发布的泛中日韩字体「思源」系列就采用了一个相对激进的做法:第一步先使用 OpenType 中的「字形组合」ccmp 特性(即 Glyph Composition),若遇到两个连续的 U+2014 字符,会将字形直接替换成到与 U+2E3A 一样的长横杠;之后的第二步,采用 GSUB 中的 locl 特性切换中日韩区域指定的字形,保证其与汉字字框居中对齐。对于三连 em dash 也采用同样处理。
第一步的做法其实非常值得向各家字体厂商推荐,因为它保证了破折号不会断开,这也是现代 OpenType 特性能服务于中文排版的少数实用功能之一。而第二步之所以说「激进」,是因为必须依靠 locl 特性进行西文与中日韩格式切换,而这不仅需要第三方应用软件的支持,还需要用户对文本本身进行正确的语言标注。也就是说,需要通过语言标记告诉软件这是中文,才能调出中式的居中字形,否则,排版软件依旧会将其认为是西文而显示西文「下沉」的字形。然而事实上,能支持语言标记的环境还非常少。当思源黑体当年刚发布时,在 Adobe 自家软件里也只有 InDesign 可用,连 Illustrator 都不支持。从用户角度说,这也加大了学习成本。从后来字体发布的反馈来看,用户非常不习惯这种做法,也不太熟悉如何调用 locl 信息,只是一直抱怨无法方便地调出正确的字形。
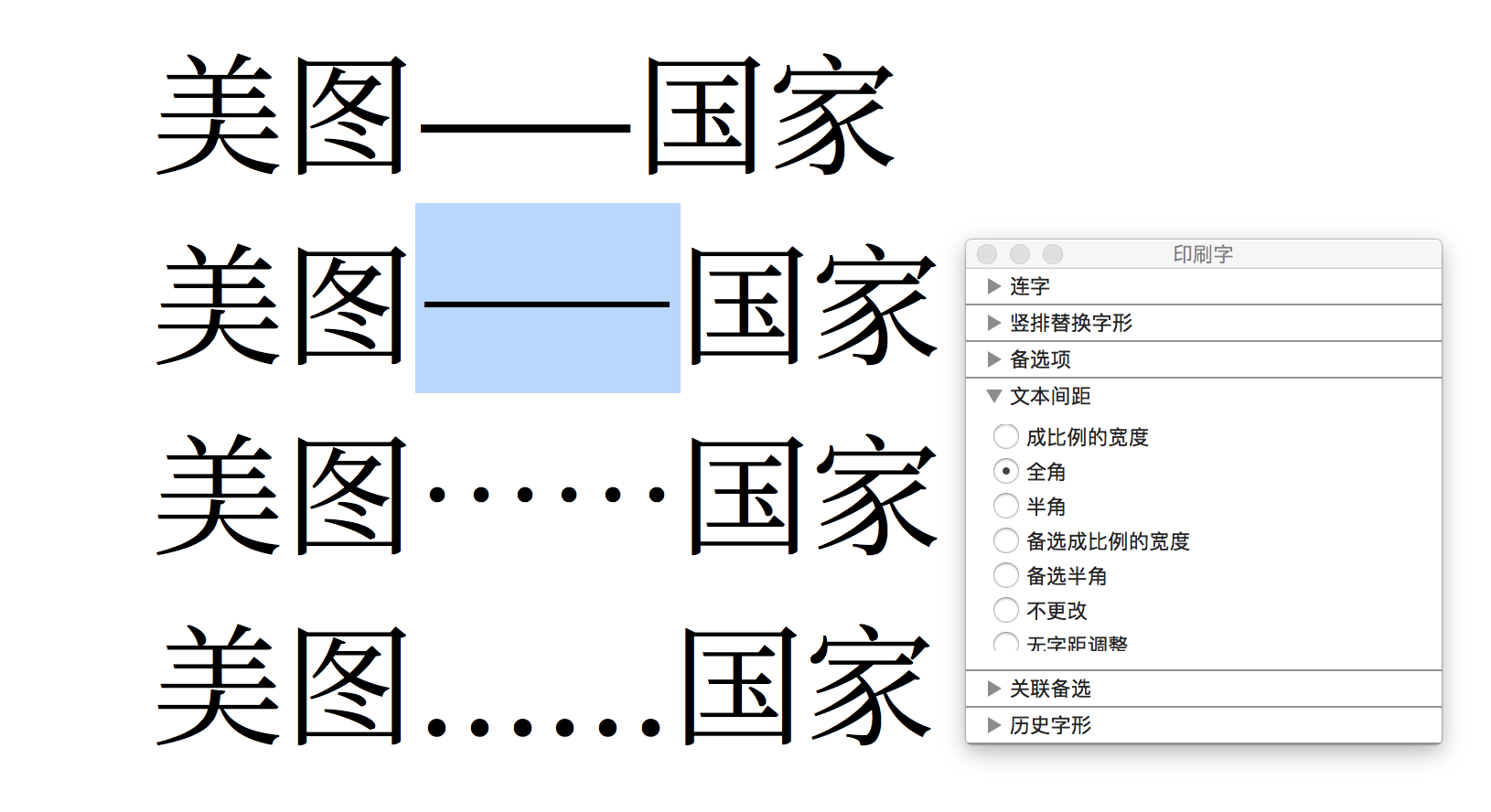
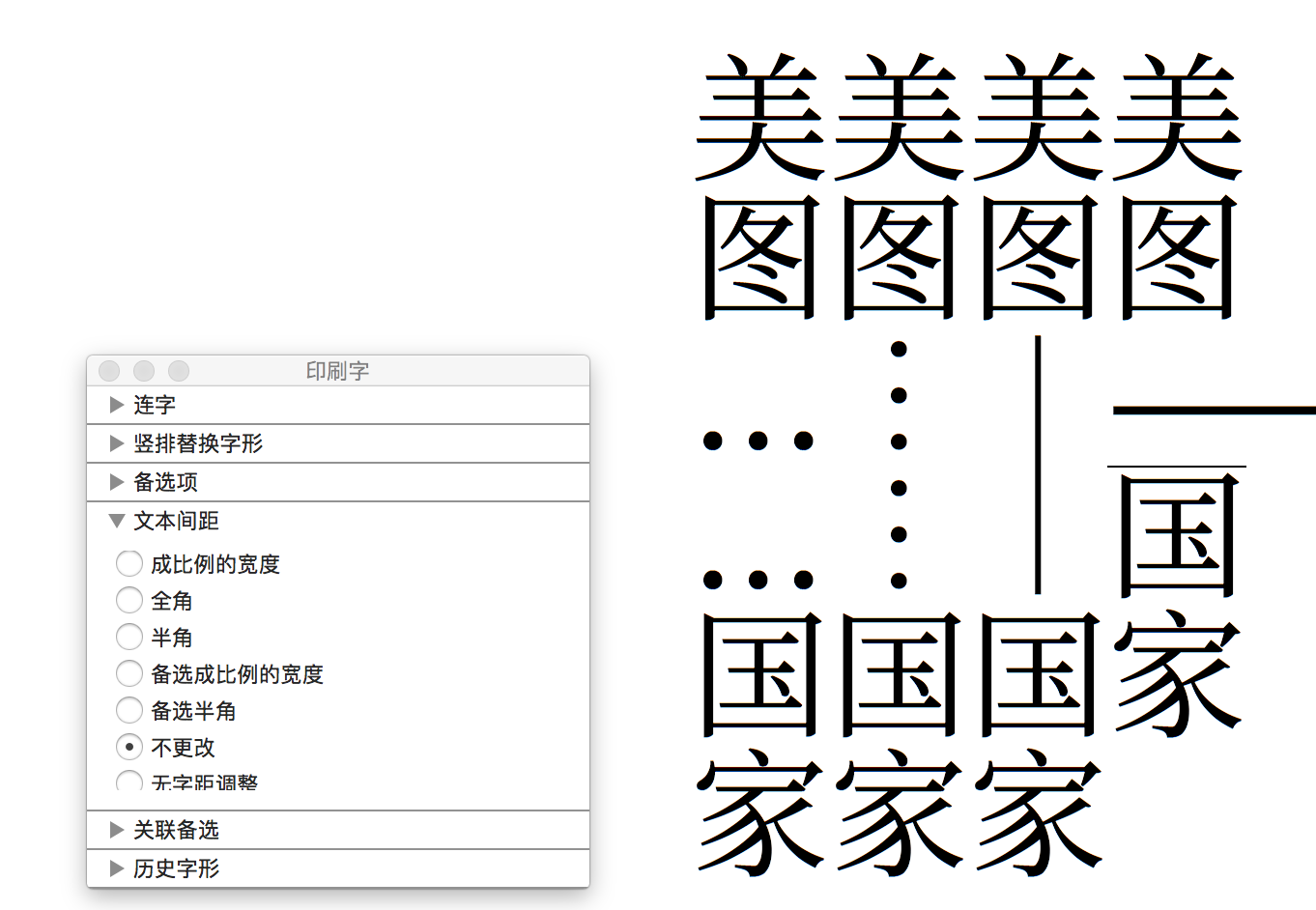
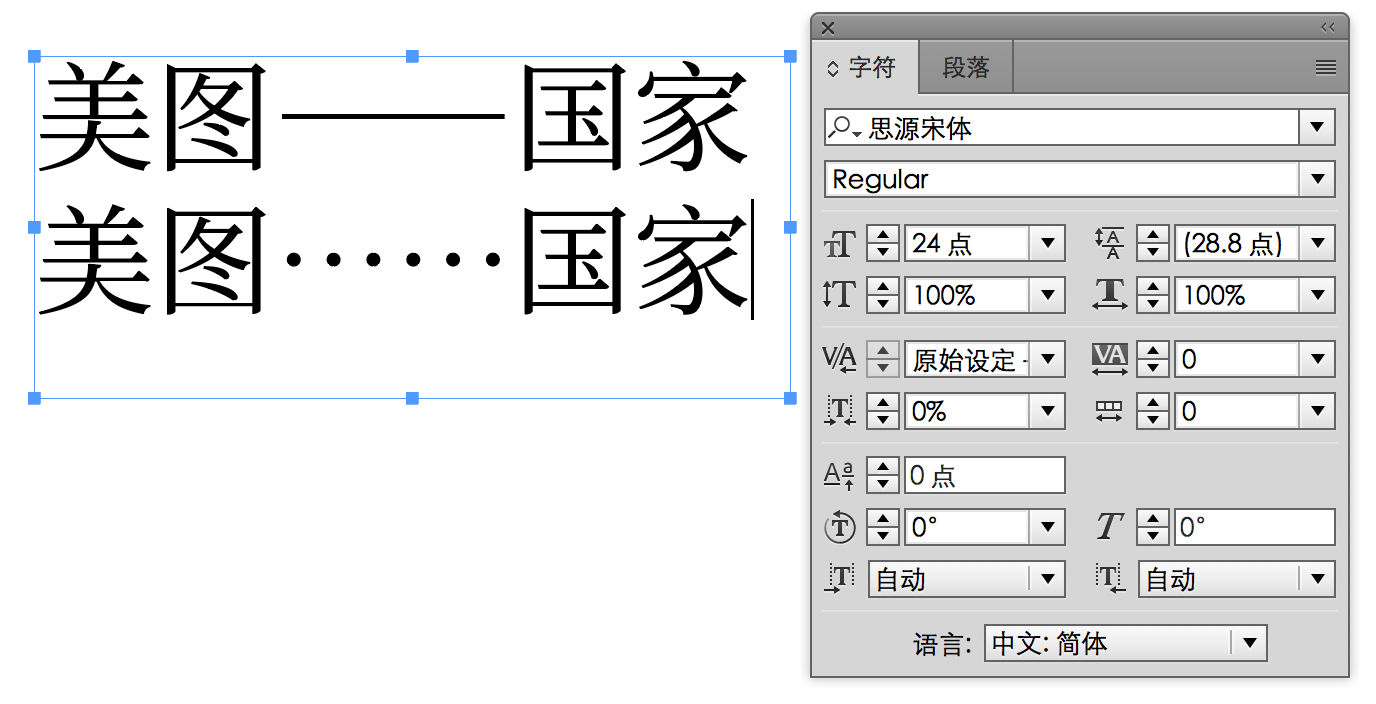
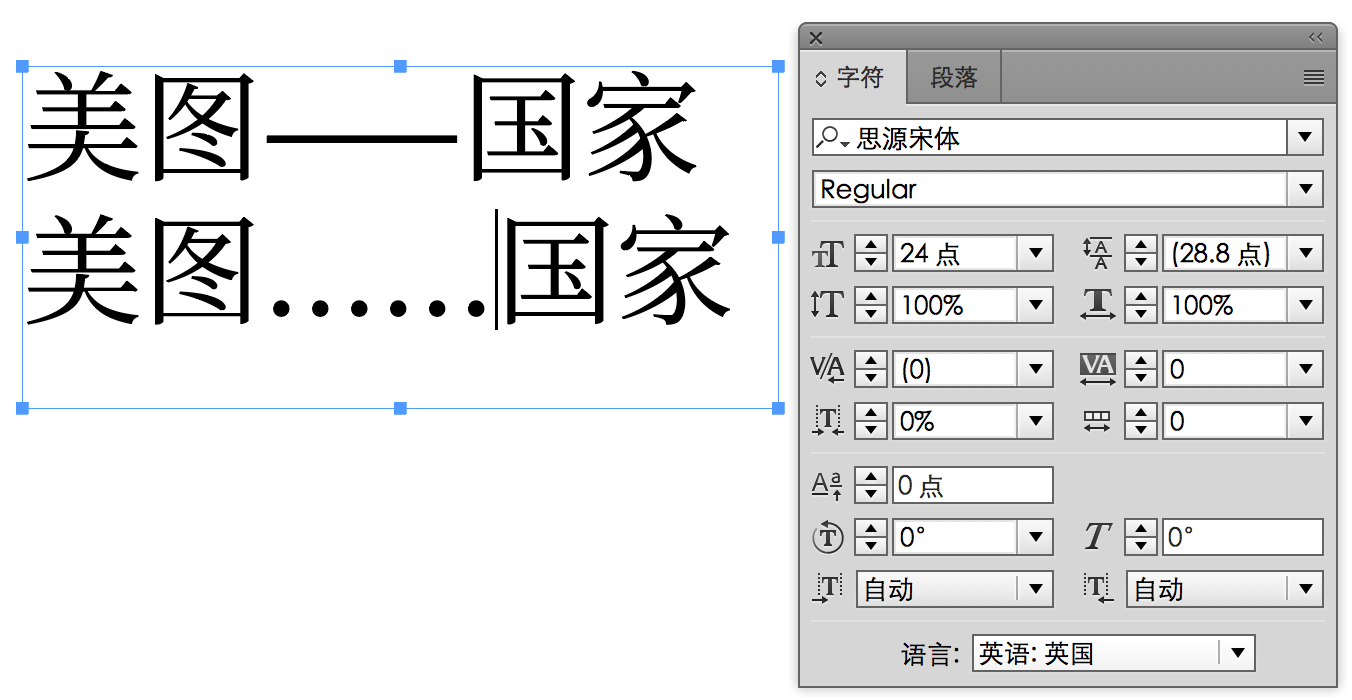
破折号怎么排版:避头避尾避中间
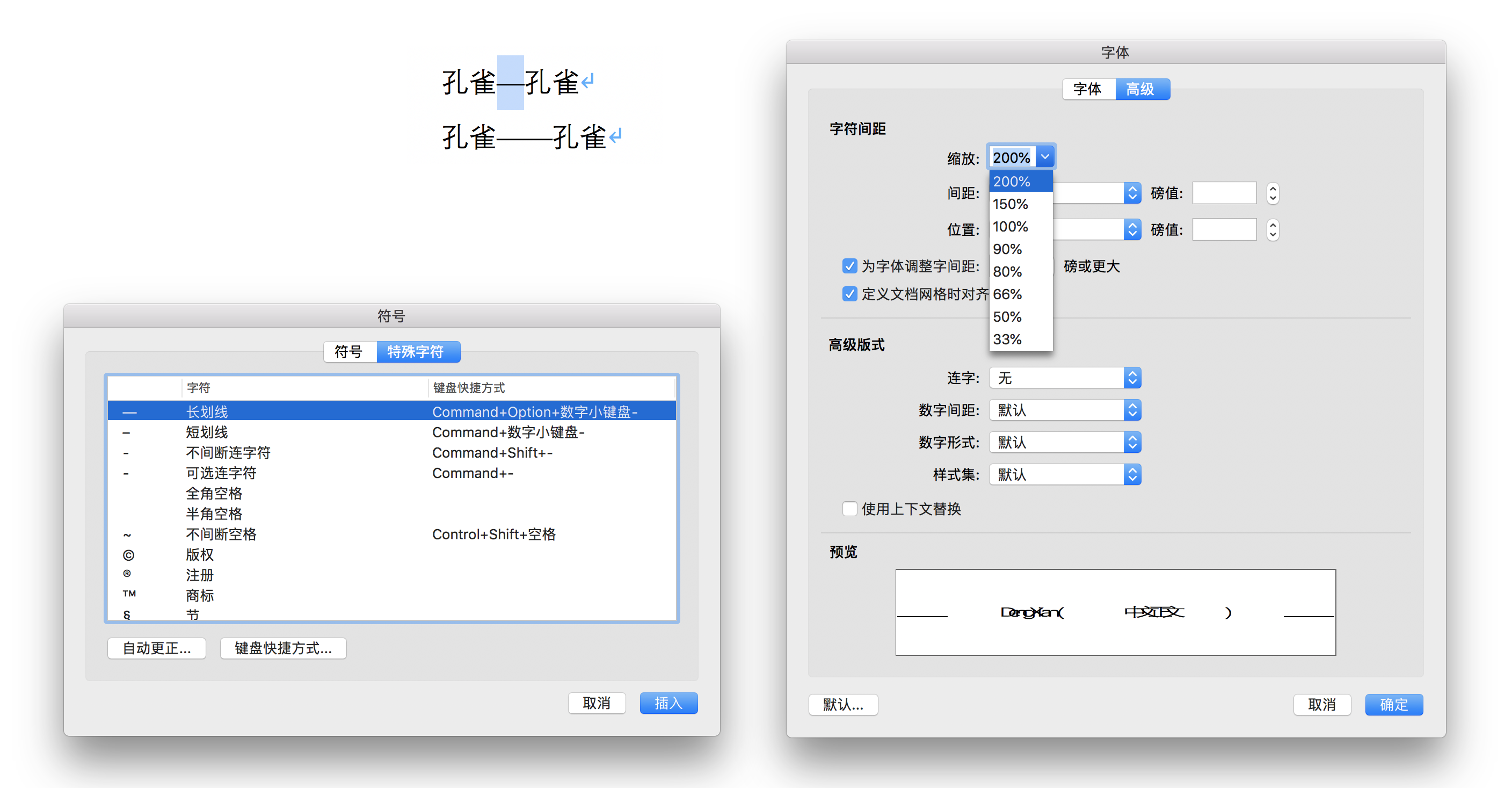
要谈破折号怎么排版,首先应该提一下一些印刷行业出身的老派编辑的做法。他们更倾向于把破折号当做其应有的「一个字符」处理,因此会靠软件里「字符变形」功能将一个 em dash 字符拉大到两倍宽。比如,在 2011 年由印刷工业出版社《排版与校对规范(第二版)》里「附录一:Word 设置的参数」里有这样记述:
符号字模未设有该符号,需要「字符缩放」完成。「插入→特殊符号→标点符号」选「—」插入后选中,「格式→字体→字符间距→缩放」选 200%
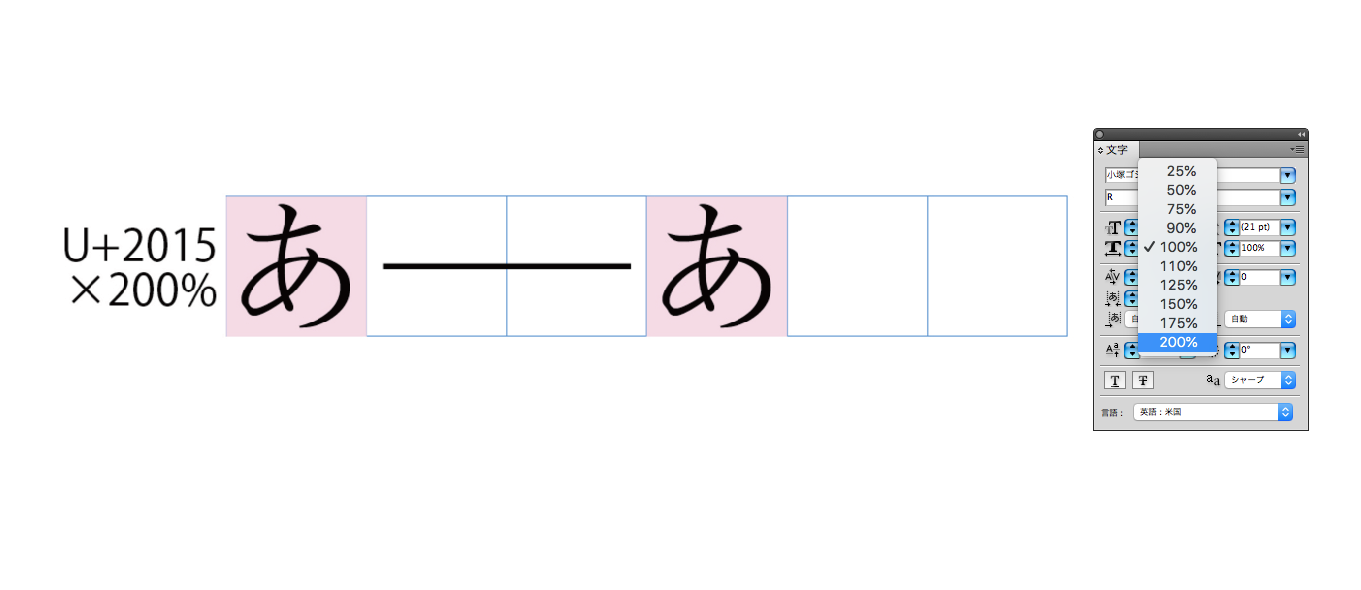
无独有偶,在特别考虑破折号的第三个长度需求时,一些日本排版专家也一直坚持在 Adobe InDesign 里不要用 U+2500 BOX DRAWINGS LIGHT HORIZONTAL 这样的制表符,因为这个符号会左右撑满。他推荐采用 U+2015 horizontal bar 字符,因为日文字库厂商往往不会将其做成左右撑满的造型,拿过来之后在软件里将其拉大到两倍宽即可。
)
使用一个字符的好处,就是在从根本上杜绝了中间断开的可能,这看似是一种曲线救国的方式,但从需求本质上说也未尝不可。当然,大部分非出版行业的朋友并不会这么做,而且接受的稿件本身绝大多数都是连用两个全角连接号去拼成一个破折号,这就容易产生从中间断开的问题。
破折号的排版还有是否需要避头尾的问题。这一点在中国国标 GB/T 15834-2011《标点符号用法》并里没有相关记述,而笔者已经在《挤进推出避头尾》一文里谈过,有兴趣的读者可以移步阅读。总体来说,有一些「严式」风格会禁止破折号出现在放在行首,但是由于这个符号占用了两个字宽,过于严格的规定往往会导致一行内产生大幅度的调整量,反而不利于长文排版的均匀字距的要求。而放宽规则,采用「宽式」风格不对破折号进行避头尾控制,其实效果并不坏。

在 Adobe InDesign 中文版默认的「简体中文避头尾」设置里,U+2014 EM DASH 已被放入「禁止在行首的字符」,也就是说,如果采用默认设置即会变成「严式」风格,对破折号进行避头处理。了解这个默认设置很重要,而需要「宽式」风格的用户可以根据需要自定义修改。
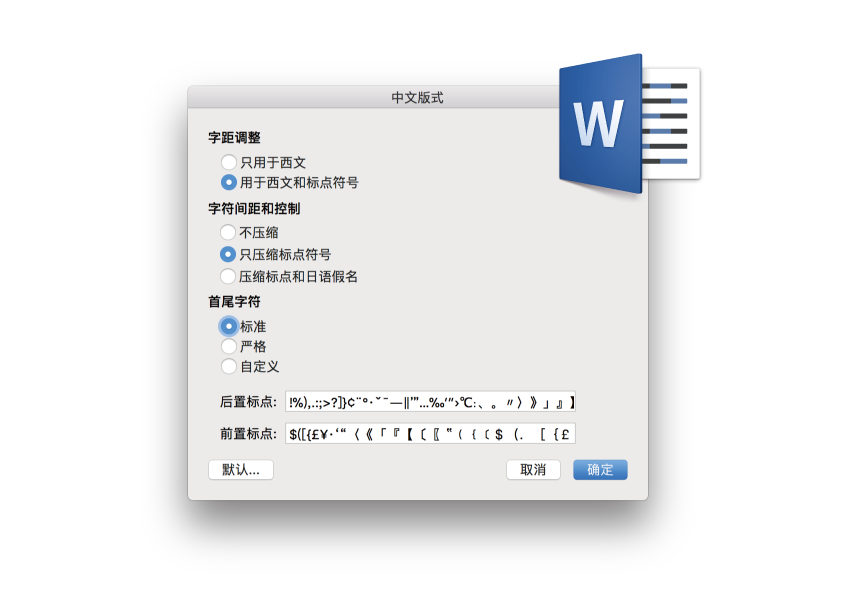
对于非设计专业的一般用户来说,需要特别注意的是微软 Word 软件的默认设置。在 Word 默认设置里「后置标点」(即避头符号)里有一个看似破折号的符号「―」,但它并不是目前大多数中文输入法采用的「—」 U+2014 EM DASH,而是 U+2015 HORIZONTAL BAR。按照这个设置,用户输入 U+2014 EM DASH 破折号时, Word 并不会对其进行避头尾处理。如果想针对破折号进行避头尾操作,笔者建议用户通过「自定义」手动添加 U+2014 EM DASH 这个符号。这个问题的根源就是本文在第二章第二节里提到的字符映射发生过修改而产生的历史问题。无论问题来源是什么,在实务操作层面,如果要确保对破折号进行避头尾处理控制,还是将两个字符都加入避头尾定义表里最为稳妥。
但是,从避头尾控制的「不可分字段」的角度考虑,破折号除了需要避头避尾,还有一个特殊的「避中间」问题,即「禁止断开」,破折号不能从中间段成两截分别位于前一行行尾和后一行行首。对于这个控制,Adobe InDesign 的操作界面却存在「禁止分开」「禁止断字」「不换行」的好几个选项,让用户非常困惑。
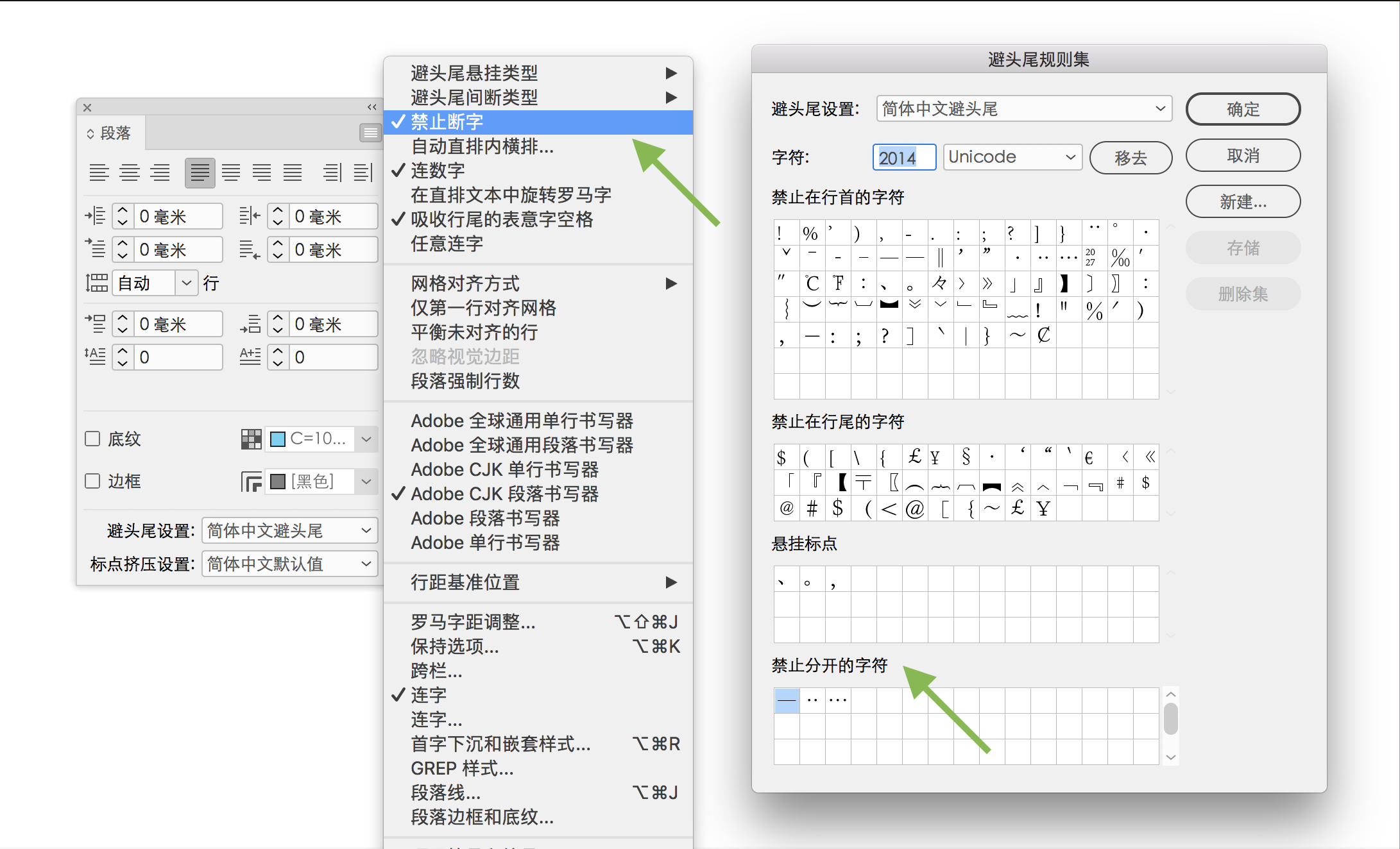
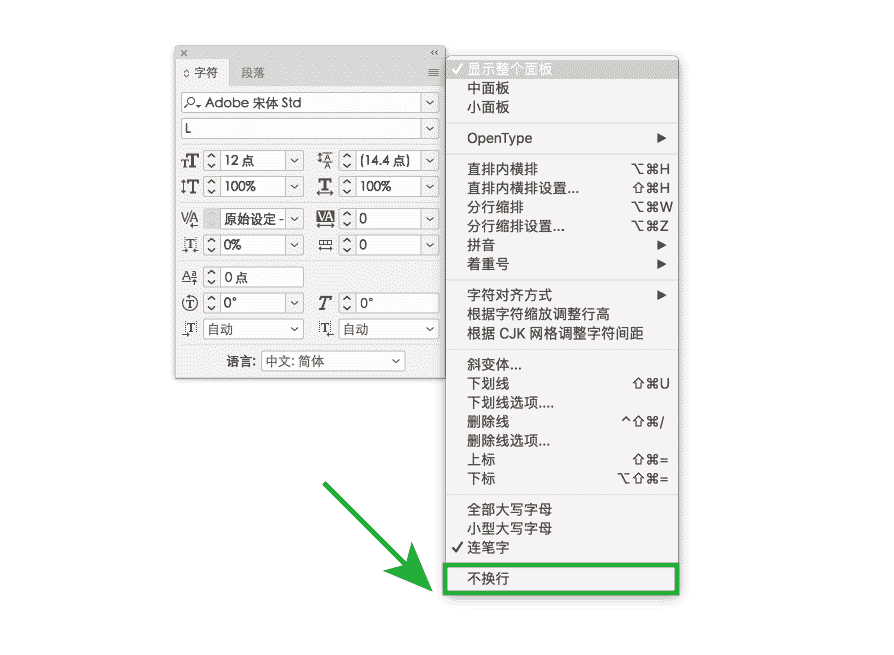
事实上,InDesign 里「字符」面板选项菜单的「不换行」原本是为西文排版准备的。在英文原版里,这个选项菜单写作 No Break,用户选择任意几个字符,再勾选这个选项之后就可以保证不会在此断开。显然这是局部的、手动指定,并不具有普适性。虽然中文破折号,也可以这样手动选择后勾选「不换行」,但如果全篇文档有十几个破折号,就必须一一手动选择进行设置,非常麻烦。
而「段落」面板里的「禁止断字」,则是和「避头尾规则集」对话框中「禁止分开的字符」定义连动的。也就是说用户需要先在「禁止分开的字符」定义里添加各种字符定义,然后才能通过勾选「段落」面板里的「禁止断字」来实现这个功能。好在「禁止断字」这个功能默认是打开状态。但是,勾选中「禁止断字」却在避头尾设置选「无」,软件失去了字符定义参照,同样不起作用。
这个「禁止断字」是 Adobe 为东亚排版而设置的功能,或者应该严格地说,这是为了实现日本 JIS X 4051「分离禁止」处理而设置的功能。翻阅 JIS X 4051 原文可以知道,日文排版所谓「分离禁止」是指字符之间不能断开,且在标点挤压等间距调整处理时也不被拉开;具体对象有破折号、省略号、「连数字」、西文单词等。显然,与「不换行」单纯功能相比,这个需求更突出了「在标点挤压等各种间距调整处理时也不被拉开」的重要性。如果忘记定义,破折号的两个字符之间在两端对齐调整字距时依旧有被断开的危险。因此,即使决定要采用「宽式」风格不避头尾,在「避头尾规则集」对话框上方里的「禁止在行首的字符」里删除掉相关字符,但依然要记着把所有这些相关字符(为了保险,建议把 U+2014、U+2015、U+2500 等等)都写入底部「禁止分开的字符」定义表里,保证「避中间」,不至于连用时从中间断开。
网页与电子书的尴尬
网页和电子书籍的排版的基础都是使用 HTML+CSS 来实现,但同样也需要从字符、字体、排版引擎等几个层面分别考虑破折号问题。对于字符码位,首先应该要留意 Unicode 标准附件第十四号《Unicode 断行算法》(UAX14) 中对几个相关字符的默认定义:
- 对于目前最常用使用的「—」(
U+2014 EM DASH),其断行属性为 B2 类,换行动作是 B/A/XP,即「前可断行、后可断行、但中间不能断开」,也就是说默认动作是「不避头、不避尾,但是避中间」; - 若使用「―」(
U+2015 HORIZONTAL BAR) 这个字符,其断行属性为 AI 类,即「不明确」,换行行为要取决于具体情况,因此要慎重。但由于其东亚宽度属性 (UAX11) 也属于 A 类「不明确」,在没有明确语言标签、文本识别、数据源等可靠参照时,会被处理 Narrow「窄字符」和西文字母一样具有 XP(中间不断开)的动作; - 如使用「⸺」(
U+2E3A TWO EM DASH)与「⸻」U+2E3B THREE EM DASH,这两个字符断行属性与U+2014 EM DASH同样是 B2 类,因此默认动作是「不避头、不避尾,但是避中间」。
开发者应该决定使用正确的码位,并了解这些字符的默认动作,然后再根据实际需要来决定是否进行额外的操作。比如目前最常见的做法是使用两个U+2014 EM DASH,其默认其实就是「宽式」避头尾原则,这是比较务实的做法。但如果要执行「严式」避头尾,则需要结合其他方法自行定义。
当然,从 CSS 定义字体的工作来说,破折号与其他标点一样,需要从系统字体的回落机制与是否定义网络字体等角度进行决策。然而,很多网页设计师为了实现「中西混排」,依照桌面排版「复合字体」的思路,按照目前 CSS 字体的回落机制,在 font-familiy 里将西文字体摆在中文字体前面,保证西文用西文字体显示。这种方式会影响数个「中西共用」的标点符号,包括蝌蚪引号和破折号在内的一些中文标点会优先按照西文字体中的字形显示,导致位置下沉或者断开等各种问题。
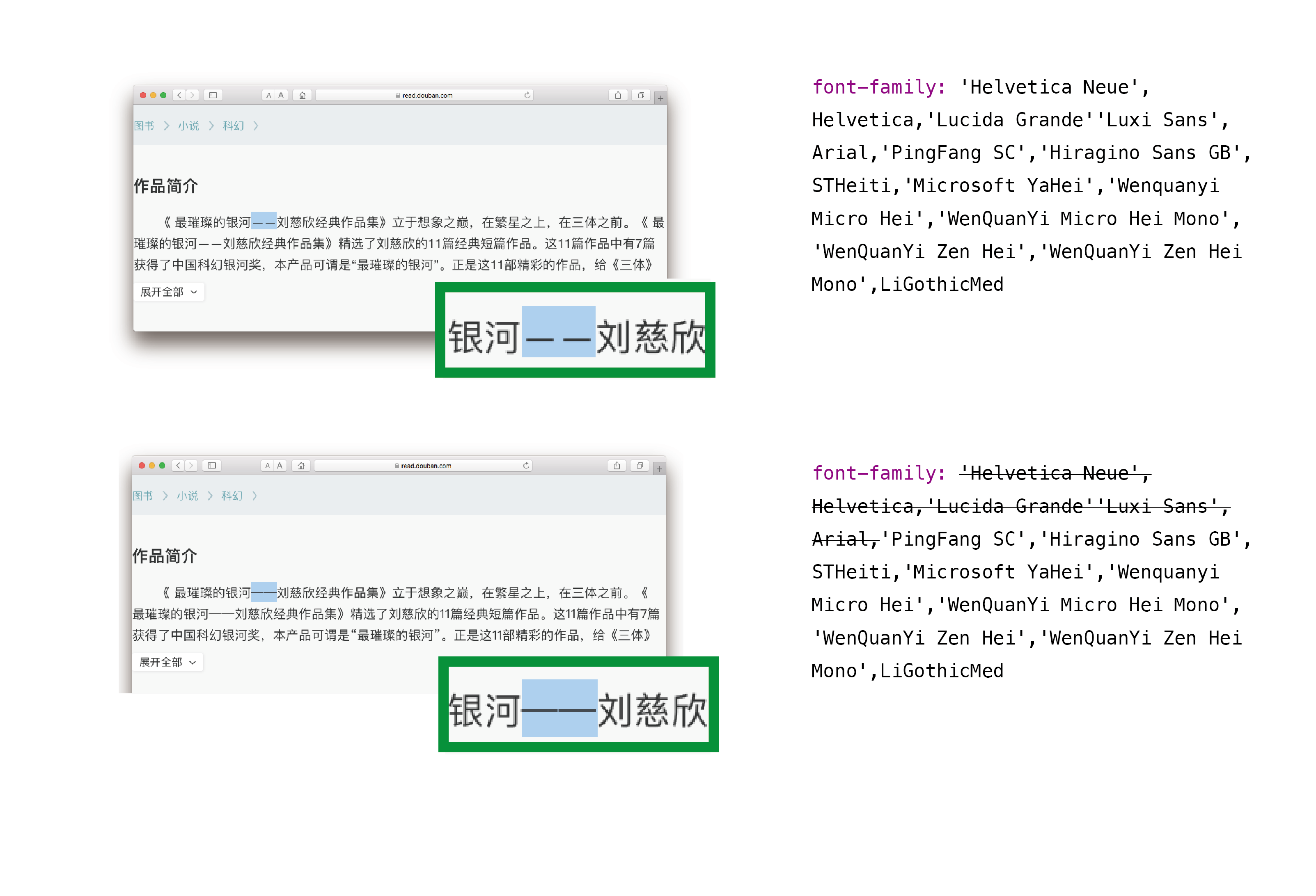
要解决这个问题有很多方法,比如可以通过额外定义 Unicode 码位范围分别定义字体,或者直接使用某款系统的中文字体或者一个已预先搭配好中西字形的字体,有能力的网站甚至自行封装一个网络字体,等等方法都能解决。如果使用思源这样支持 locl 标签的字体,还应该在合适的地方(比如 <lang> 语言标签)进行语言声明。最终效果可以通过比对实际调用的字形来分析解决,需要多尝试,毕竟选择一个靠谱的字体是进行正确排版的第一步。
小结
破折号这一现代中文里常见的标点符号,经常由于各种原因无法被正确地输入、显示。本文从最基本的需求出发,指出破折号原本应该是一个符号而不是两个字符的拼接,中间不能断开,位置要位于汉字字框的上下中央,虽然占两格但其长度最好不要撑满。在目前的实际操作中,已多用拼接两个「—」(U+2014 EM DASH) 字符来表示破折号,但移动设备系统的输入法的界面还有待改善,以便以更友好的方式让用户输入。而字库厂商则应该学习 Adobe 制作「思源」系列字体的第一步做法,提供更为精准完美的「占两格却不撑满」的字形,积极采用 OpenType 的 GSUB 特性让用户在输入两个连续 U+2014 EM DASH 时能自动替换成正确的字形。而在排版方面,最重要的应该是保持破折号不被断开,这一点无论是在字处理软件还是专业平面设计软件都有相应的设置,并且在实务操作上应该考虑周全一些,对相关的若干个字符都进行统一定义,保证没有漏网之鱼。至于破折号的避头尾问题,中国目前的推荐国标根本就没有提及,而实际上「宽式」的「不避头尾」原则已经足够,毕竟避头尾规则过于严格容易导致调整量加剧,因此在排版风格决策的时候要谨慎处理。而网页和电子书排版时,要特别注意 CSS 的字体回落机制对显示造成的影响,针对实际效果在各个环境下进行调试。
不要小看破折号这样一根横杠,其牵涉的这些问题,其实都是当代中文字体排印发展历史和现状的一个折射。不吃透中文内在的实际需求而生搬硬套西文的符号,会导致扭曲的实作,一步错而步步错,之后会为向后兼容和迂回处理而付出更惨重的代价。而且,字体排印从需求、码位、输入法、字库、排版引擎到显示印刷的最终效果,每个环节都会牵一发而动全身。正因如此,才需要我们从整体的角度全盘考虑才能把问题解决得更透彻。
其实不仅是破折号,现代中文排版里必须的连接号、省略号,以及在网络上吵得沸沸扬扬的直角引号与蝌蚪引号之争,其背后都有各种各样类似的问题,本文选择破折号为阐述对象,是因为破折号汇集了各种问题于一身。以破折号为切入口理清各种问题,这些经验对其他各种「问题标点」都会有借鉴意义。只有这样才能整体提高标点符号的可用性,为实现一个有逻辑的中文排版打好基础。
注:
- 《芝加哥风格手册》(The Chicago Manual of Style,第 17 版)第 6.83 节指出:「按英国用法,在长文中,比起 em dash 通常更偏好使用一个 en dash(前后加空格);也有一些非英国出版社追随这种方法。」而在《新牛津风格手册》(New Oxford Style Manual, 2016 版)第 4.11.1 节中也指出「很多英国出版社用 en rule 前后加空格作为插入用的 dash 符号,但是牛津风格和大部分美国出版社使用 em rule。」↩︎
鸣谢
感谢柳东原先生对本文的协助
参考书目与资料
- 于光宗.排版与校对规范(第二版).北京:印刷工业出版社,2011.
- GB/T 15834-2011 《标点符号用法》
- JIS X 4051:2004 『日本語文書の組版方法』
- The University of Chicago Press, The Chicago Manual of Manual of Style, 17th Edition, 2017
- Oxford University Press, New Oxford Style Manual, 2016